A prior is conjugate for a given likelihood if both the prior and posterior have the same parametric form.
We will see in the next chapter that all likelihoods from the exponential family have conjugate priors. Here we look at a few examples.
(Binomial sample.) Suppose our likelihood model is , and we wish to make inferences about , from a single observation .
So
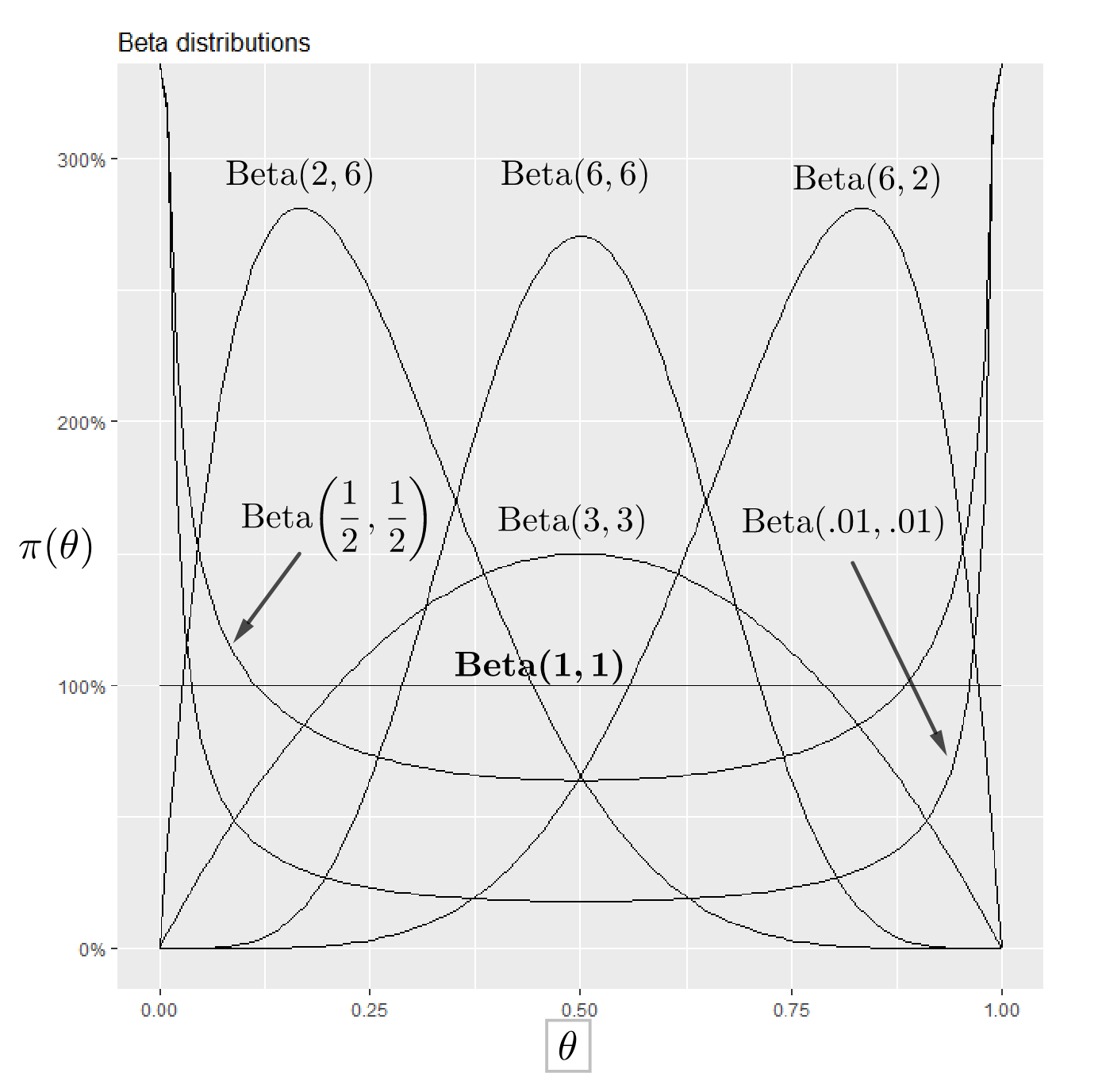
So, in this case, suppose we can represent our prior beliefs about by a beta distribution:
so that
The parameters of this distribution are an d . (They are NOT probabilities and may have any positive value.) The mean and variance of this distribution are
The Beta distribution is written as
We call the beta function; don’t confuse it with the distribution.
Bayes Rule Now we apply Bayes Theorem using this prior distribution:
There is only one density function proportional to this, so it must be the case that
The updates are
| (Updates for Beta prior with a Binomial likelihood) |
In other words, the number of successes to added to the first parameter of the Beta and the number of failures to the second parameter. This does not have to be done all at once. It can be done observation by observation.
Sequential updating of belief in a parameter
.
If the data consists of a sequence of shots on goals by a player. They are denoted by Then our belief in the ability of the player can be updated sequentially.
The expected sucess rates are
Let us take an example of a run of successes and failures in a basketball game. For each success . For each failure
y <- c(1, 0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 1, 1, 0, 0, 1, 1, 1, 1, 1,
1, 1, 1, 0, 1, 1, 0, 1, 1, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0)
ΨΨ#several rows ommitted
p <- 1 ;q <- 1
mean <- rep(0, 200); uq <- rep(0, 200); lq <- rep(0, 200)
for (i in 1:200) {
p <- p + y[i]
q <- q + 1 - y[i]
mean[i] <- p/(p + q)
lq[i] <- qbeta(0.025, p, q)
uq[i] <- qbeta(0.975, p, q)
}
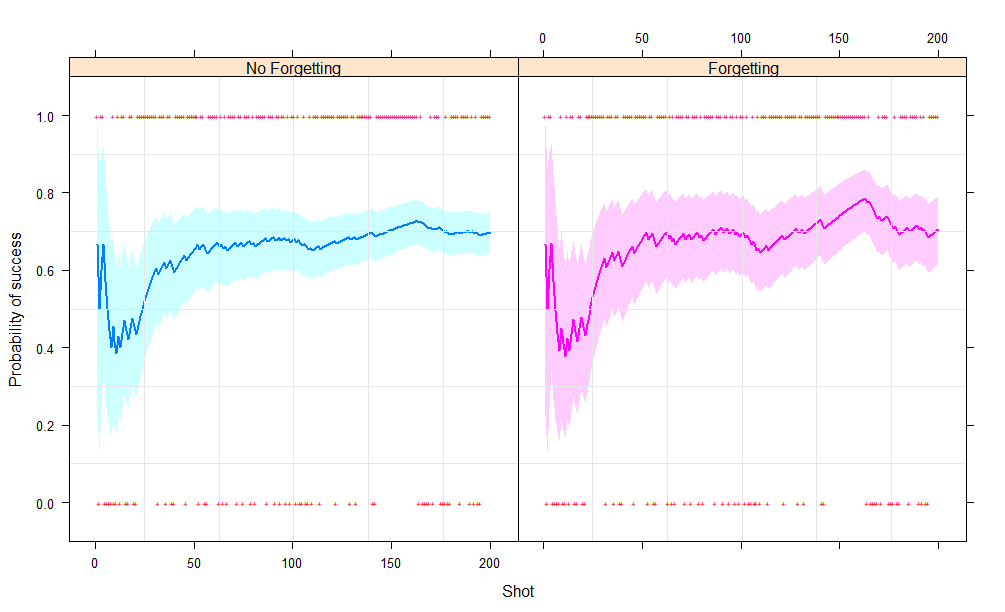
In stationary models (when is fixed) as more and more observations are made we become more and more certain about the parameter an intervals for the parameter () become narrower.
In a model with forgetting, the parameter changes with time. A good example of this is when is the current form of a current sports team. As the team changes the form of the team changes. When changes recent results are judged more relevant than the results of games from the distant past.
Click this link for a good video on Bayesian inference on a beta distribution: https://www.coursera.org/learn/bayesian/lecture/xFRKb/inference-on-a-binomial-proportion ‘
Suppose we have a random sample (i.e. independent observations) of size , of a random variable whose distribution is Poisson Then
As in the binomial example, prior beliefs about will vary from problem to problem, but we’ll look for a form which gives a range of different possibilities, but is also mathematically tractable.
case we suppose our prior beliefs can be represented by a gamma distribution:
so
The parameter is a shape parameter, and is a scale parameter. The mean and variance of this distribution are
Assume we have a Poisson likelihood with a gamma prior then by applying Bayes’ Theorem with this prior distribution we get,
Again, there is only one density function proportional to this, so it must be the case that
This is nother gamma distribution whose parameters are modified by the sum of the data, , and the sample size . The updates are
| (Updates for Gamma prior with a Poisson likelihood) |
A nice video example on Poisson-Gamma conjugacy: https://www.coursera.org/learn/bayesian-statistics/lecture/tR5ne/lesson-8-1-poisson-data
Let us take an example of drug arrest from a particular patrol car and update our parameters sequentially: and .
y <- c(0, 1, 0, 0, 7, 0, 0, 0, 0, 0, 1, 3, 0, 4, 0, 1, 0, 2, 2, 0, 0, 0,
0, 0, 0, 0, 0, 2, 0, 0, 0, 3, 1, 0, 0, 1, 0, 0, 0, 0, 2, 1, 0, 1, 0,
0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 3, 0, 0, 0, 2, 0, 0, 4, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
3, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 1, 2, 1, 0,
0, 0, 1, 2, 1, 2, 11, 2, 4, 0, 2, 4, 7, 5, 12, 6, 4, 6, 0, 4, 9, 4,
8, 7, 2, 9, 10, 16, 19, 2)
p <- 1; q <- 1;n <- length(y)
mean <- rep(0, n); luq <- rep(0, n);lq <- rep(0, n)
for (i in 1:n) {
p <- p + y[i]; q <- q + 1; mean[i] <- p/q
lq[i] <- qgamma(0.025, p, q); uq[i] <- qgamma(0.975, p, q)
}
The panel on the left shows drug related reports, The posteriors are calculated sequentially. Here all observations are considered equally. Note how the uncertainty expected number of drug arrests (the shaded region) goes down in time. In the second panel the past is downweighted and recent history is emphasised.
Let denote the home team and denote the away team and the games in chronological labelled as .
| (Likelihood for goals of home team ) | |||||
| (Likelihood for goals of away team) |
where denotes the attacking strength of team , is the defensive strength of team and is the common home ground advantage. The priors for the Poisson model are given below. is fixed at say .
| (Priors for attacking strengths) | ||||
| (Priors for defensive strengths) | ||||
| (Priors for home ground advantage) |
Let us say Liverpool is playing Arsenal at Home. The prior attacking and defensive strengths before the game are
Let us say Liverpool win 4-1.
Find the expected attacking strength, defensive strengths and HGA before the game.
Find the prior expected score.
Write out the likelihood for the scores of the home and away teams.
Find the posterior distributions of all five parameters.
Update the Gamma parameters for their attacking and defensive strengths, and HGA after game.
Which teams improved their attacking strength and defensive strengths?
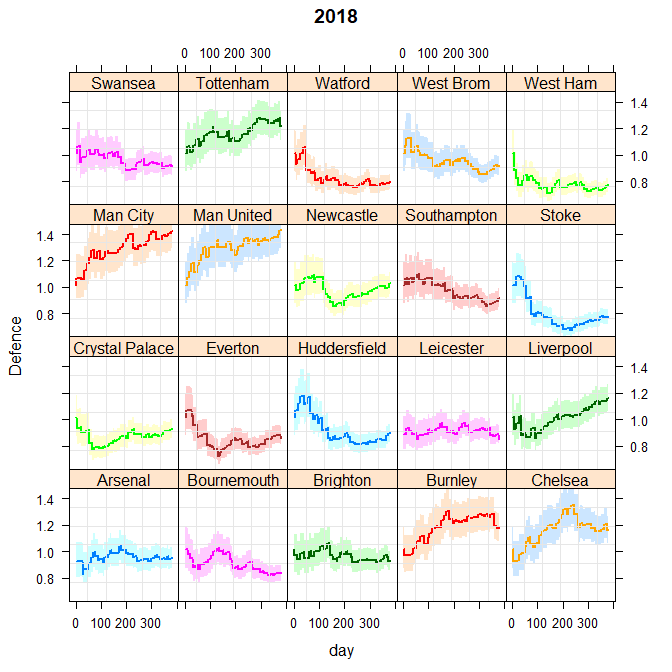
Attacking strength shown through the 2017-18 football league season. All goals are modelled as Poisson. All teams start with the same prior (ie the same ability). The shaded region shows the region between the upper and lower quartiles.
Inference for the mean of normally distributed data
Let be a random sample of size of a random variable with the Normal distribution, where is assumed known. The likelihood is better desribed using the precision .
The following is a useful result for identifying normal distributions. If is a parameter with probability density function satisfying
iff
PROOF
We now pair up the likelihood with a prior for .
| (The likelihood) | ||||
| (The prior) |
We now show that the conjugate prior for the mean of the normal using the result above
| (1.1) |
Prior precision = .
Sample precision = .
Posterior Precision .
Posterior precision = prior precision + sample precision
Prior mean = .
Sample mean = .
Posterior mean
=.
Posterior mean = weighted sum of the prior mean and the sample mean
ESS of a Gaussian prior with respect to a Gaussian sample .
Observations to be made A number of observations can be made:
Note that the effective sample size or .
Observe that ‘posterior precision’ = ‘prior precision’ + ‘precision of each data item’.
As , then (loosely)
so that the prior has no effect in the limit.
As uncertainty contained in the prior increases or , or equivalently the prior precision decreases or , we again obtain
Note that the posterior distribution depends on the data only through and not through the individual values of the themselves. Again, we say that is sufficient for .
Let us take an example data set :Yearly suicides in Australia per 100000 individuals. We update the mean one observation at a time. Bayes theorem gets applied at each time step using the previous mean, , in the prior for the current mean .
| (The Prior ) | ||||
| (The Likelihood ) | ||||
| (The Posterior) | ||||
Let
Since is fixed then will also be fixed. Thus the prior is .
| (The prior) | ||||
| (The likelihood) | ||||
| (The posterior) |
The normal distribution (mean, , known) So the updates for the parameters of the Gamma distribution are
| (Updates for Gamma prior with a normal likelihood) |
The Laplacian distribution is useful for modeling distributions with heavy tails such as those found in stock-market returns. We model the returns as
where has a density given by
where is not the precision. The Laplacian has a variance given by . In volatility modelling we are interested in how the variance of observations change (not the mean). We set the mean of the Laplacian to zero.
When the prior is given as , The posterior becomes
So the updates for the Gamma distribution are
| (Updates for Gamma prior with a Laplacian likelihood) |
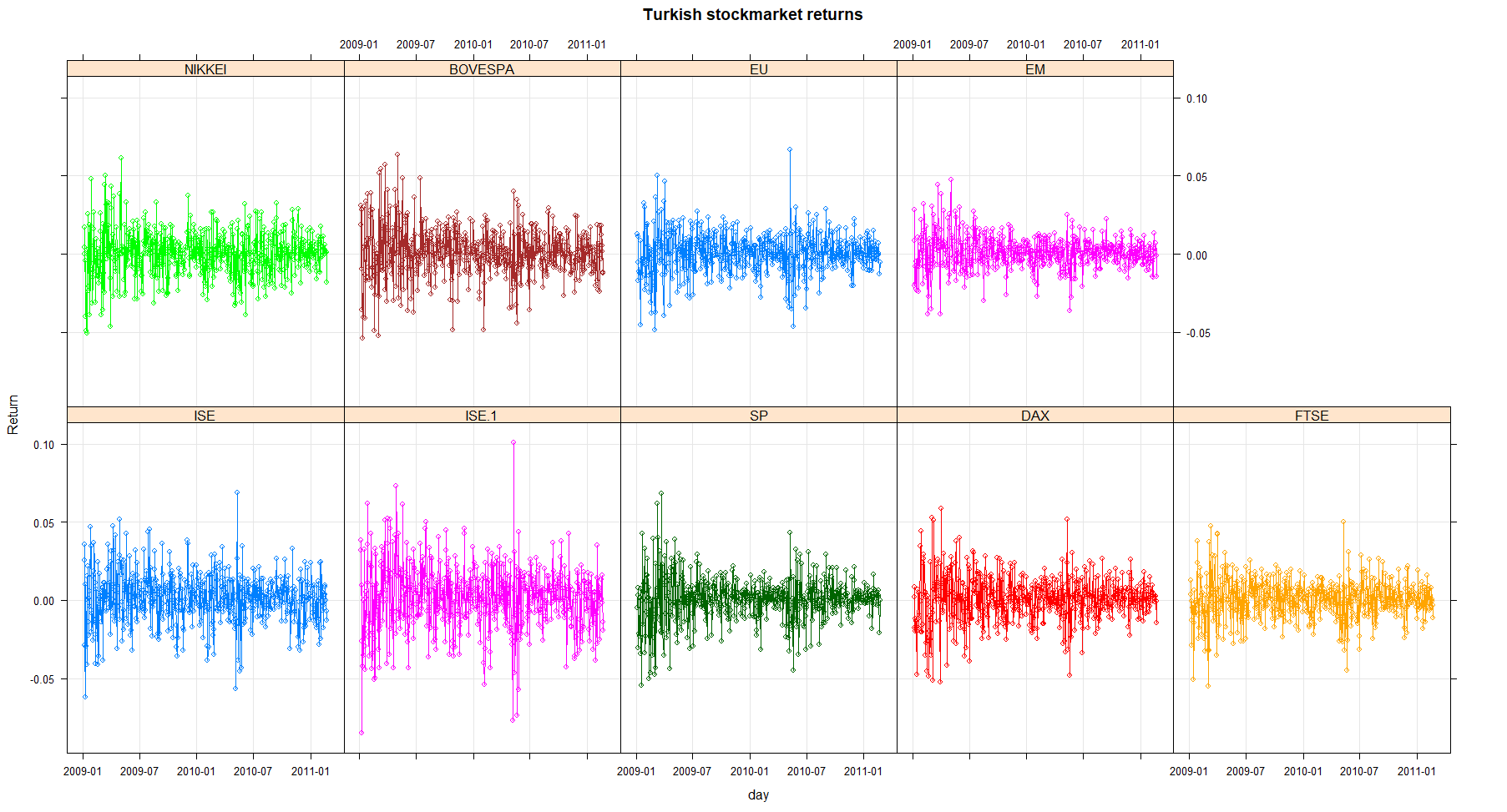
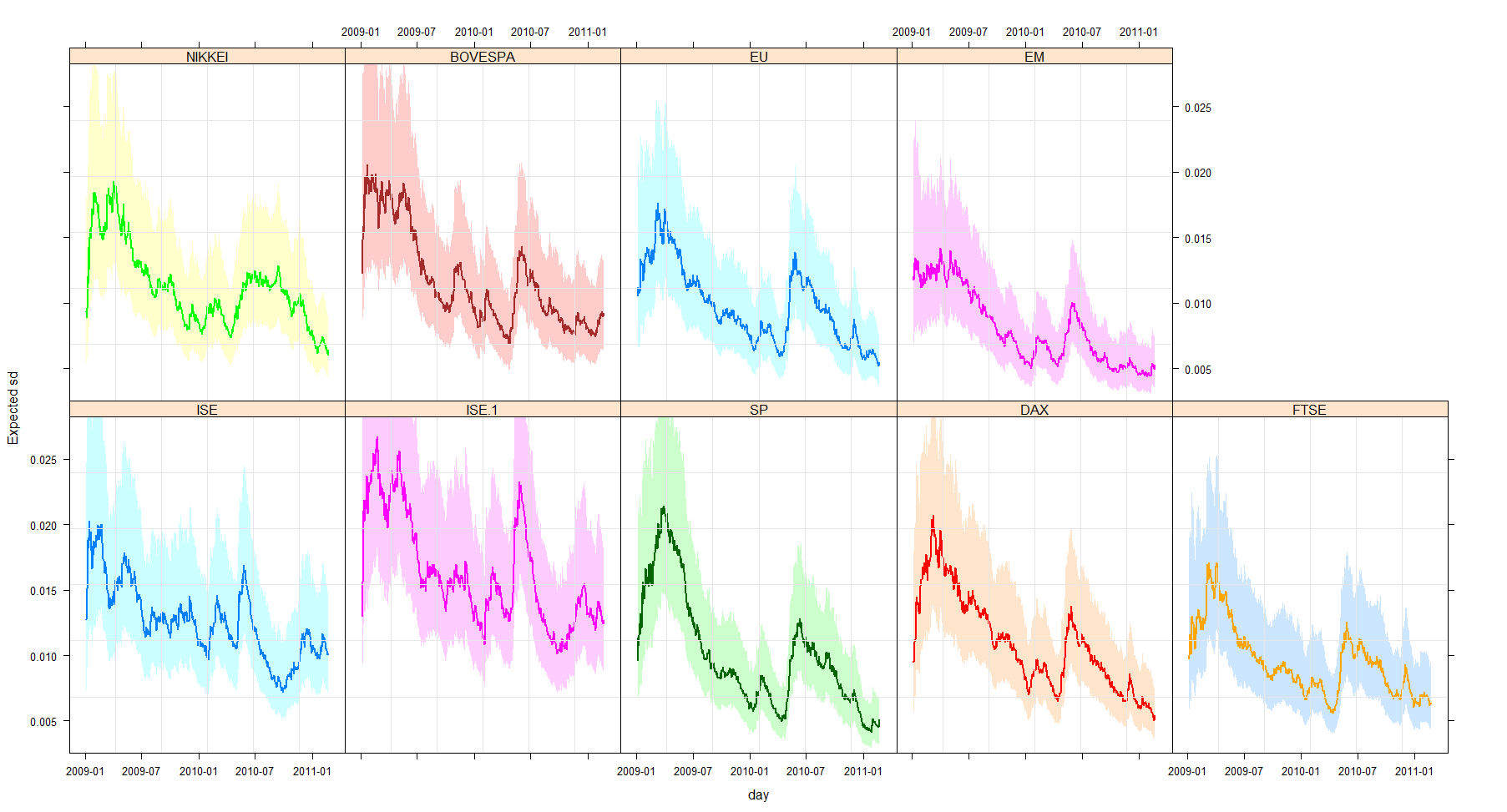
Lehman Brothers filed for bankruptcy on 15 September 2008, prompting a fall in the FTSE 100 of 4%. It was the beginning of a slump that by Christmas of that year had resulted in 23.4% being wiped off the value of Britain’s top 100 companies.
In a matter of minutes (May 2010) the Dow Jones index lost almost 9% of its value in a sequences of events that quickly became known as ”flash crash”. Hundreds of billions of dollars were wiped off the share prices of household name companies. But the carnage, which took place at a speed never before witnessed, did not last long. The market rapidly regained its composure and eventually closed 3% lower. In just 20 minutes, 2 Bn shares worth $56 Bn had changed hands.
A dataset that illustrates these shocks is shown here
| ISE100 | Istanbul stock exchange national 100 index |
| SP | Standard & poor’s 500 return index |
| DAX | Stock market return index of Germany |
| FTSE | Stock market return index of UK |
| NIK | Stock market return index of Japan |
| BVSP | Stock market return index of Brazil |
| EU | MSCI European index |
| EM | MSCI emerging markets index |
Let be independent variables having the Gamma distribution, where is known.
Now, studying this form, regarded as a function of suggests we could take a prior of the form
that is, , since then by Bayes’ Theorem
and so . So the updates for the Gamma distribution are
| (Updates for Gamma prior with a Gamma likelihood) |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}