The normal distribution is a commonly encountered distribution (because of the central limit theorem) and therefore important. Bayesian inference on the normal becomes a little more difficult because there are at least two unknowns rather than one. There are a variety of ways of carrying Bayesian inference on these two parameters and the method depends on the priors being used. Let be a set of independent variables from Let be a set of independent variables from Normal , where both the mean and variance are denoted by and respectively. Then,
| (4.2) |
so
| (4.3) |
and and therefore will have fully conjugate priors.
Again assuming i.i.d. Gaussian likelihood which can be expressed as
Also let the sample mean sum of the squares be respectively be and . The likelihood can then be expressed as
If we choose an improper prior of , the joint distribution becomes
The joint posterior is a product of these two distributions.
| (4.4) |
The marginal distribution of can be obtained by marginalisng from the joint distribution.
This is a kernel of a Gamma distribution so
Finally, consider a location and scale change to :
Then
This is the density of a –distribution with degrees of freedom. That is:
To find the predictive distribution a double integral must be carried out.
This is easily done by carrying out these two steps
Condition on and integrate out : using
ntegral in (1) can be done easily using the identities for the marginal means and variances. The integral in (2) is straightforward. These integrals are not done here and are part of the coursework for this chapter. It can be shown that
Also let the sample mean and variance respectively be and . The likelihood can then be expressed as
As a function of and this is a product of a kernel of a Normal for and a Gamma for .
This parametrization of the likelihood suggests the following steps.
Express the priors of and as a four parameter Normal-Gamma distribution
Rewrite the likelihood so it has the same form.
By using the four parameter Normal-Gamma form of the prior.
The likelihood can be rewritten as
This suggests a prior of the form
where the updates to the sufficient statistics are
In addition the predictive and the marginal are also available in closed from
The predictive
The marginal
By completing the square we can show that
It can be further shown that
By comparing with the prior
we can show that
and have the hierarchical prior structure:
| (4.9) |
Multiplying by the likelihood
We get
| (4.10) |
where the updates to the sufficient statistics are
| () |
The updates are
| () |
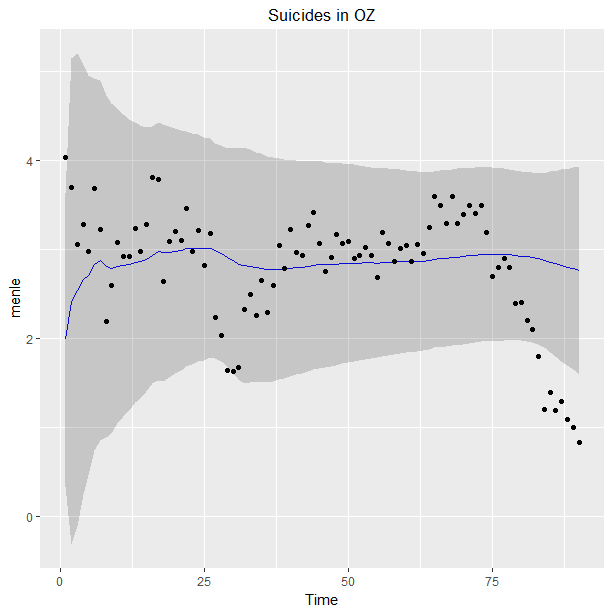
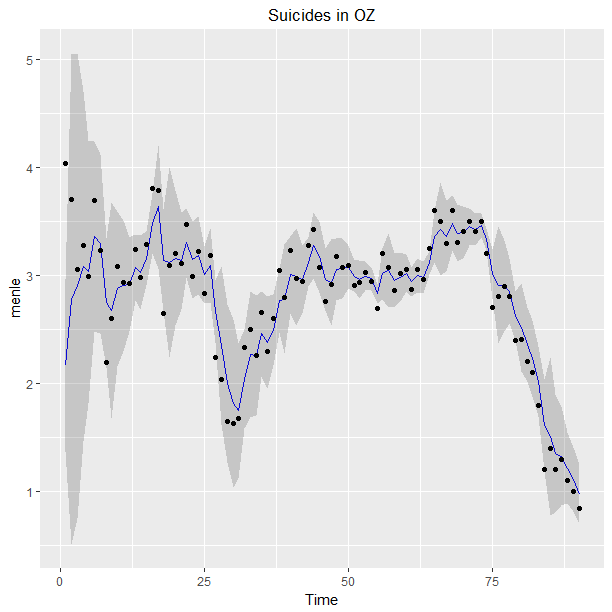
#Australian deaths y=c(0.522, 0.425, 0.425, 0.477, 0.828, 0.616, 0.367, 0.431, 0.281, 0.465, 0.269, 0.578, 0.566, 0.508, 0.751, 0.681, 0.766, 0.456, 0.498, 0.419, 0.61, 0.457, 0.571, 0.348, 0.387, 0.582, 0.239, 0.237, 0.263, 0.424, 0.365, 0.375, 0.409, 0.389, 0.24, 0.159, 0.439, 0.509, 0.374, 0.434, 0.413, 0.329, 0.519, 0.549, 0.547, 0.496, 0.531, 0.596, 0.557, 0.573, 0.501, 0.543, 0.559, 0.691, 0.44, 0.568, 0.597, 0.474, 0.592, 0.598, 0.633, 0.606, 0.705, 0.481, 0.703, 0.701, 0.603, 0.698, 0.598, 0.802, 0.602, 0.599, 0.603, 0.702, 0.5, 0.498, 0.498, 0.6, 0.334, 0.274, 0.321, 0.541, 0.405, 0.289, 0.328, 0.313, 0.258, 0.214, 0.186, 0.159
omega=.5 #The forgetting parameter.
i=0;m=1;n=1;a=2;b=1;
mn=rep(0,length(y)); uq=rep(0,length(y));lq=rep(0,length(y))
while (i<length(y))
{
i=i+1
a0=omega*a
b0=omega*b
m=m0+(1/(1+n0))*(y[i]-m0)
n=n0+1
a=omega*a0+.5
b=omega*b0+(.5*n0)/(n0+1) *(y[i]-m0)^2
mn[i]=qnorm(.5,m0,sqrt(b0/a0))
uq[i]=qnorm(.95,m0,sqrt(b0/a0))
lq[i]=qnorm(.05,m0,sqrt(b0/a0))
m=m1;n=n1; a=a1; b=b1
}
{kind=link}
{kind=link}