How to Perform Online (or Real-Time) Changepoint Detection in Python
In the world of data analysis, detecting changes in data streams is a crucial task. This article will guide you through performing online (or real-time) changepoint detection using Python’s changepoint_online package, to identify abrupt shifts in your data streams as quickly as they arrive.
Changepoint detection is a statistical technique used to pinpoint moments in a time series where the underlying characteristics of the data significantly change, such as a change in the mean, variance, or distribution of the data. This can be invaluable in various applications, from monitoring financial markets for sudden price fluctuations to tracking sensor readings for equipment failures.
Online changepoint detection, in particular, is useful when dealing with large datasets or real-time data streams. It allows us to detect changes in the data as they occur, rather than waiting until the end of the dataset, and this can be particularly useful in monitoring applications where timely detection is critical.
The changepoint_online package offers a powerful and versatile toolkit for online changepoint detection, based on the Focus algorithm. Focus algorithm boasts a complexity of O(log(n)) per iteration, making it ideal for processing large data streams efficiently, even with low training observations.
The package supports various univariate and multivariate distribution families, including Gaussian, Poisson, Gamma, and Bernoulli. This allows you to tailor the analysis to your specific data type. It can handle scenarios where the pre-change parameter is known or unknown, providing adaptability to different use cases, and allows you to impose constraints, enabling detection of specific change types (e.g., increases or decreases).
If you have found the
changepoint_onlinepackage useful, or encountered any limitations or issues, please get in touch – we would love to hear from you!
Getting Started
The changepoint_online package is readily available through PyPI. Here’s how to install it:
Installing from GitHub: (recommended for getting the latest features)
python -m pip install 'git+https://github.com/grosed/changepoint_online/#egg=changepoint_online&subdirectory=python/package'
Using pip:
pip install changepoint-online
Detecting a Change in Mean for Univariate Gaussian Distribution
As a first example, here, we’ll demonstrate how to detect a change in mean for a univariate Gaussian distribution using the changepoint_online package. We’ll simulate some data with a shift in mean at a specific point and then use the package to pinpoint this changepoint.
Simulating the Data
First, we’ll import the necessary libraries and generate some sample data that embodies a change in mean.
import matplotlib.pyplot as plt
import numpy as np
# Set random seed for replicability
np.random.seed(0)
# Define data means and sizes
mean_pre = 0.0
mean_post = 2.0
size_total = 50000 # Total data size
# Generate data with a changepoint in the middle
Y = np.concatenate((np.random.normal(loc=mean_pre, scale=1.0, size=int(size_total / 2)),
np.random.normal(loc=mean_post, scale=1.0, size=int(size_total / 2))))
To generate the example in this snippet, we define the means (pre-change and post-change) and the total data size (size_total), and defined the pre-change and post-change segments by dividing the total size in half. This generates a changepoint in the middle, as it can be seen in the plot below:
# Plot the data to visualize the changepoint
plt.plot(Y)
plt.axhline(y=mean_pre, color='b', linestyle='--', label='Pre-change Mean')
plt.axhline(y=mean_post, color='r', linestyle='--', label='Post-change Mean')
plt.xlabel('Data Point')
plt.ylabel('Data Value')
plt.title('Sample Data with Change in Mean')
plt.legend()
plt.grid(True)
plt.show()

Online Changepoint Detection
Time to run our changepoint analysis! In real-world monitoring scenarios, data typically arrives as a stream. The changepoint_online package is designed for this type of online or real-time analysis. Imagine the data is continuously fed into a buffer, and the changepoint detection algorithm analyzes this buffer to identify potential shifts in the underlying distribution.
For the sake of this article, wesimulates this process by iterating over the data points one by one. In a streaming application, the loop would be replaced by a mechanism to pull data from the buffer whenever new data arrives.
from changepoint_online import Focus, Gaussian
# Initialize a detector for Gaussian distribution
detector = Focus(Gaussian())
threshold = 13.0
for y in Y:
# Sequentially update the detector with each data point
detector.update(y)
if detector.statistic() >= threshold:
break
print(detector.changepoint()) # Print the detected changepoint
{'stopping_time': 25004, 'changepoint': 25000}
After 25,000 data points, We detected our change point only after 4 iterations!
Explanation:
- We create a detector object specifying a Gaussian distribution (
Focus(Gaussian())). and we set a threshold (threshold = 13.0) for the detection statistic. In this example we go with a fixed threshold, however this can be tailored to each application needs.
The core loop iterates through the data (Y), mimicking how the detector would process a stream of data points arriving one at a time:
-
Inside the loop, each data point
yis fed to the detector usingdetector.update(y). This function internally updates the detector’s statistics to track the evolving data stream and identify potential changepoints. -
The
detector.statistic()function calculates the current value of the detection statistic. This statistic quantifies how likely a change has occurred based on the data seen so far. -
If the detection statistic surpasses the predefined threshold (
threshold), it suggests a significant shift in the data stream is probable. We break out of the loop and assume a changepoint has been detected at the current position (index) within the data. -
Finally, we print the detected changepoint index using
detector.changepoint(). This indicates the point in the simulated data stream where the change was most likely to happen. In a real-world application, the changepoint detection would occur continuously as new data arrives.
The changepoint_online package can also detect changes in one-parameter exponential family distributions, such as Poisson change-in-rate, useful for count data, Gamma change-in-scale (or rate), for positively defined data, and Bernoulli change-in-probability, for binary data.
For more comprehensive examples and applications involving various distributions, refer to the detailed vignettes available on the project’s GitHub repository https://github.com/grosed/changepoint_online. These vignettes provide in-depth explanations and code demonstrations tailored to specific use cases.
More examples
Non-Parametric Changepoint Detection with Unknown Distribution
The changepoint_online package also offers non-parametric changepoint detection using the NPFocus algorithm. This is beneficial when the underlying data distribution is unknown or the change nature is unpredictable beforehand.
Here, we simulate data with a changepoint, but unlike previous examples, the data is a combination of Gamma distributions with added Gaussian noise, making the underlying distribution less clear.
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(123)
# Define a simple Gaussian noise function
def generate_gaussian_noise(size):
return np.random.normal(loc=0.0, scale=1.0, size=size)
# Generate mixed data with change in gamma component
gamma_1 = np.random.gamma(4.0, scale=6.0, size=5000)
gamma_2 = np.random.gamma(4.0, scale=3.0, size=5000)
gaussian_noise = generate_gaussian_noise(10000)
Y = np.concatenate((gamma_1 + gaussian_noise[:5000], gamma_2 + gaussian_noise[5000:]))
# Plot the data to visualize
plt.plot(Y)
plt.xlabel('Data Point')
plt.ylabel('Data Value')
plt.title('Sample Mixed Gamma Data with Change')
plt.grid(True)
plt.show()
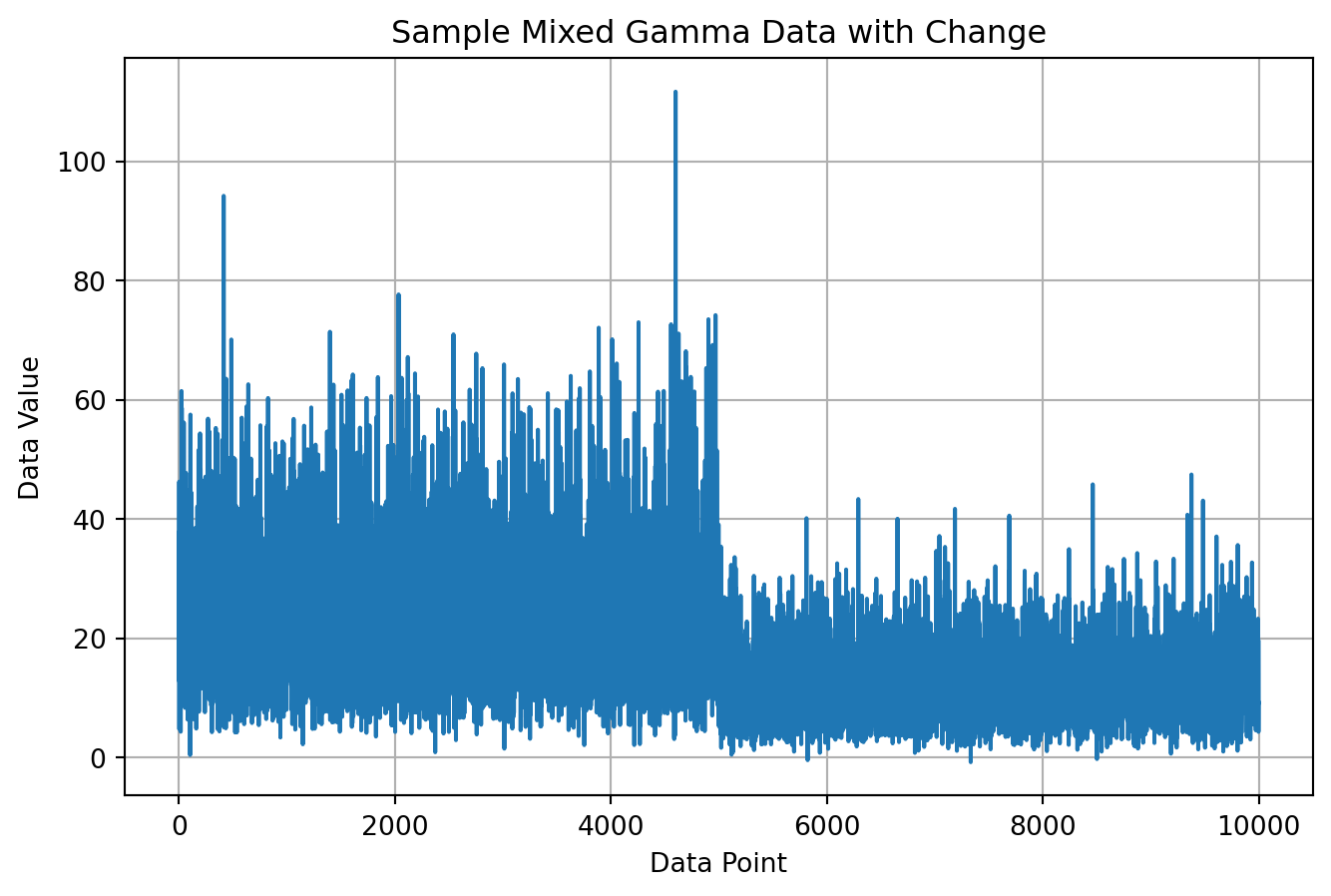
Now, we’ll leverage NPFocus to detect the changepoint in this mixed, non-parametric data. With NPFocus, we don’t make assumptions about the underlying data distribution. To address this, the algorithm monitors quantiles of the data stream. When you initialize the detector, you provide initial quantiles, such as the 25th percentile (dividing the data into fourths, marking the first quartile) or the median (splitting the data in half). These quantiles essentially act as markers to monitor different portions of the data distribution.
As new data arrives, NPFocus calculates separate statistics for each provided quantile. These statistics track how the distribution of data points around those specific quantile values evolves over time. Significant deviations in a particular quantile’s statistic can signal a changepoint affecting that portion of the distribution. For instance, a substantial rise in the statistic for the 95th percentile (representing the upper tail) might indicate a change towards more extreme values in the data. In our example, we use the 25th, 50th (median) and the 75th percentile:
from changepoint_online import NPFocus
import numpy as np
# Define initial quantiles for the null distribution (we use the first 100 observations as training data)
quantiles = [np.quantile(Y[:100], q) for q in [0.25, 0.5, 0.75]]
# Create the NPFocus detector
detector = NPFocus(quantiles)
# Track statistics over time (optional for visualization)
stat_over_time = []
for y in Y:
detector.update(y)
# Implement your stopping rule here (e.g., if sum(statistic) > threshold)
if np.sum(detector.statistic()) > 25: # Example stopping rule (adjustable)
break
changepoint_info = detector.changepoint()
print(changepoint_info["stopping_time"])
5019
This quantile-based approach offers flexibility. By monitoring only the most extreme quantiles (for example, the 1st percentile and 99th percentile), you can focus on changepoint detection in the tails of the distribution. Conversely, using a broader range of quantiles makes the detector more sensitive to changes across the entire distribution, as demonstrated in the example where the sum of statistics was used. In essence, NPFocus allows you to tailor the analysis to specific parts of the distribution where change is most relevant to your application.
Multivariate Data
It is possible to run a multivariate analysis via MDFocus, the Focus generalization, by feeding, at each iteration, a numpy array. Here’s an example of detecting a Gaussian change-in-mean:
from changepoint_online import MDFocus, MDGaussian
import numpy as np
np.random.seed(123)
# Define means and standard deviations for pre-change and post-change periods (independent dimensions)
mean_pre = np.array([0.0, 0.0, 5.0])
mean_post = np.array([1.0, 1.0, 4.5])
# Sample sizes for pre-change and post-change periods
size_pre = 5000
size_post = 500
# Generate pre-change data (independent samples for each dimension)
Y_pre = np.random.normal(mean_pre, size=(size_pre, 3))
# Generate post-change data (independent samples for each dimension)
Y_post = np.random.normal(mean_post, size=(size_post, 3))
# Concatenate data with a changepoint in the middle
changepoint = size_pre
Y = np.concatenate((Y_pre, Y_post))
# Initialize the Gaussian detector
# (for change in mean known, as in univariate case, write MDGaussian(loc=mean_pre))
detector = MDFocus(MDGaussian(), pruning_params = (2, 1))
threshold = 25
for y in Y:
detector.update(y)
if detector.statistic() >= threshold:
break
print(detector.changepoint())
{'stopping_time': 5014, 'changepoint': 5000}
In conclusion, changepoint_online is a versatile and efficient Python package for online changepoint detection. It offers a wide range of features and is easy to use, making it a valuable tool for anyone working with data streams. Whether you’re dealing with univariate or multivariate data, known or unknown distributions, changepoint_online has got you covered. For any question, don’t hesisitate to drop me a message :)