I had the chance to approach a series of statistical learning methods during the first MRes topic sprint. One of them was Bayesian optimisation, a technique for efficient global optimization of functions that can be evaluated but have an unknown structure.
It turns out that in fields such as robotics, computer vision, chemical engineering, and geology, the need to optimise such a “black box” occurs quite often. Each evaluation of the black box also usually carries a considerable cost—at best, this means running a computer for a long time and at worst, directly paying for it. Knowing very little about what we want to optimise, getting even close to the optimum seems hopelessly expensive.
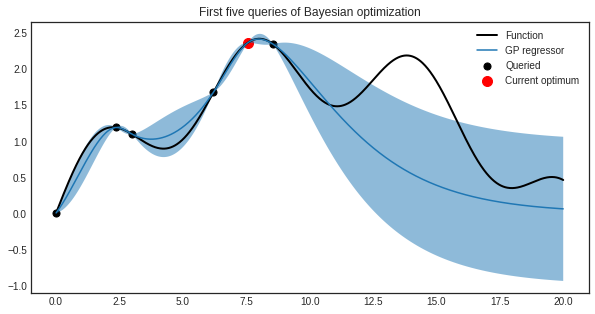
Thanks to the power of statistics however, this need not be the case. We can “learn” the function iteratively by Bayesian modelling: we start with a basic model, evaluate the function at some point(s), use this information to improve our model—rinse and repeat. The model of choice is usually a Gaussian process which, combined with the simple idea of choosing to evaluate where we think we would improve our current best guess the most (highest expected improvement), can achieve remarkable results.
So remarkable, in fact, that it was a major contributor to the success of Google Deepmind’s AlphaGo, the program that beat 18-time Go world champion Lee Sedol four to one in an iconic match in 2017. Go is an immensely complex game, and its mastery was thought to be out of reach of artificial intelligence for at least another decade until that moment. Deepmind’s researchers used Bayesian optimisation to improve the brain of AlphaGo using the same idea outlined above. This lead to AlphaGo winning an impressive 70% more often, an improvement that would likely not have been achieved otherwise.
If that still doesn’t convince you of the power of Bayesian optimisation, check out how it finds the optimum of the function below using only twelve points.
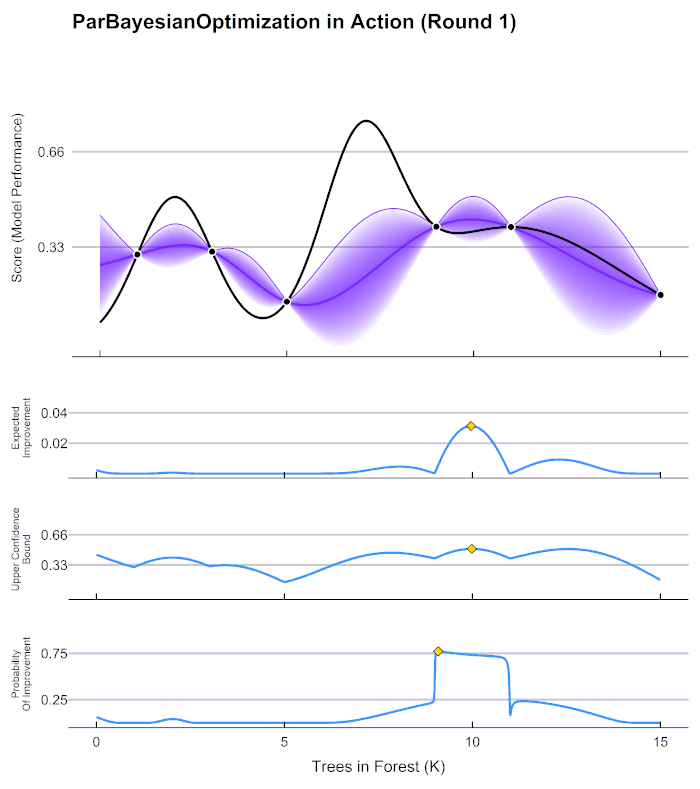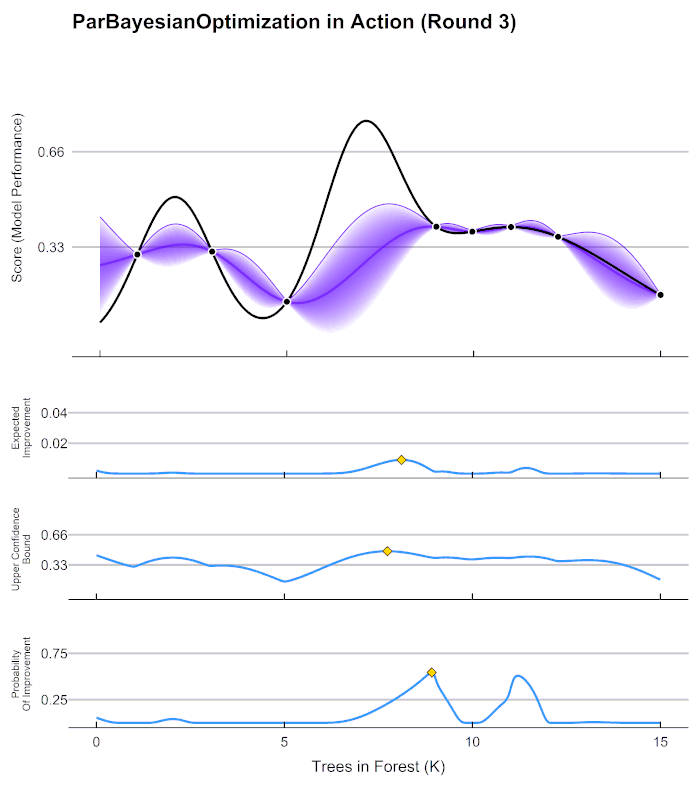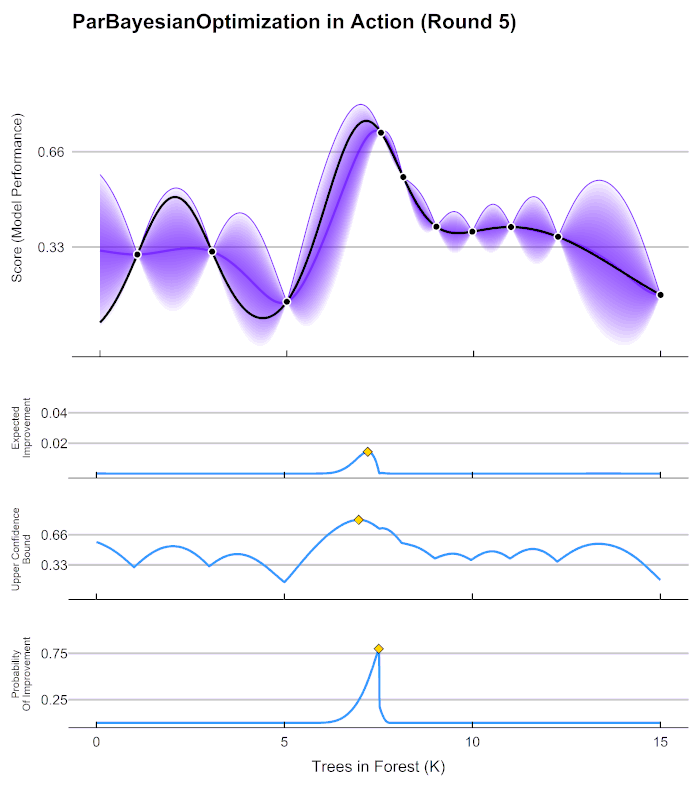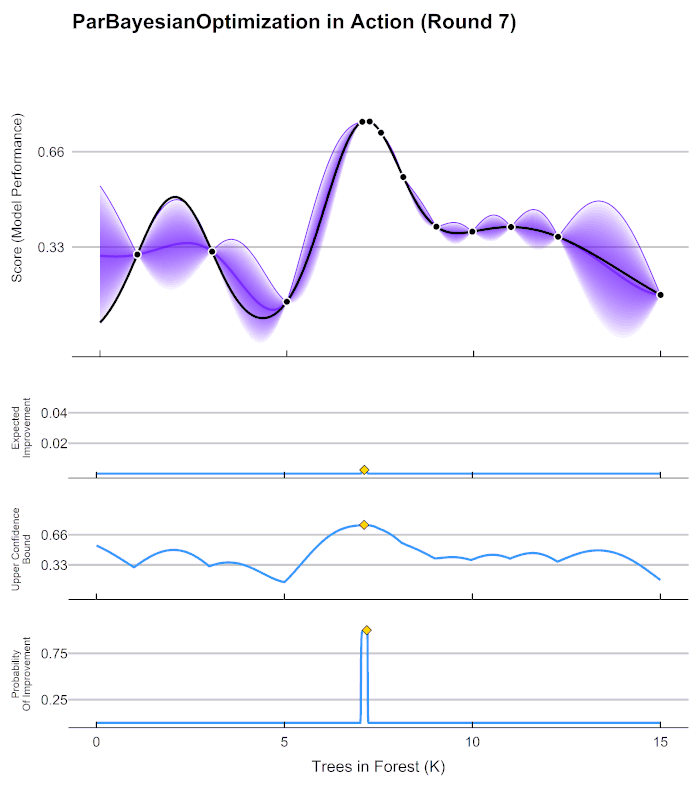

1 Response
[…] with some parameters in order to achieve this with confidence, and so you’ve decided to use Bayesian optimisation to cut down on time. You still need to run your robot on the full course every time you evaluate, […]