A few weeks ago, Professor Brendan Murphy visited Lancaster University to present a two-day masterclass to all STOR-i students on Model-Based Clustering and Classification. Brendan is Full Professor and Head of School in School of Mathematics and Statistics at University College Dublin. His research interests include clustering, classification and latent variable modelling, particularly Brendan is interested in applications from social sciences, food science, medicine and biology. Currently, he is the editor for Social Sciences and Government for the Annals of Applied Statistics and he has recently co-authored a research monograph on Model-Based Clustering and Classification
Intro
Brendan kick-started the masterclass by providing an introduction to clustering. Cluster analysis aims to find meaningful groups in data in order to find clusters whose members have something in common that they do not share with members of other groups. Clustering dates back to the beginning of language – at least – when objects were grouped according to common characteristics. For example, Aristotle classified animals into groups based on observations, in ‘History of Animals’ from the 4th century BC.
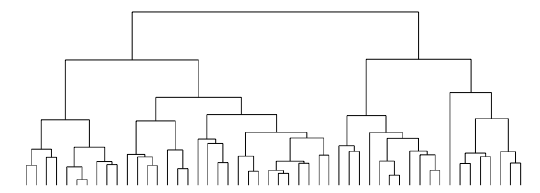
Hierarchical Clustering
In the 1950s, various hierarchical clustering methods were introduced. These aim to build a tree of clusters so that you start with n observations divided into n clusters (every observation is its own, individual cluster), then you find the two ‘closest’ clusters and group them so that there are now n-1 clusters, then you continue in this way until everyone is in a cluster. In order to do this, you need a measure of distance between observations (dissimilarity) and a measure of distance between clusters (linkage). The choice of these measures can heavily influence the results. Hierarchical clustering doesn’t always perform well even though it is commonly used.
K-means Clustering
Another method of clustering was developed in the late 1950s: k-means clustering. Here, we describe clusters by the average of the observations within it. This is an iterative algorithm repeated until convergence, split into two steps:
Allocation: assign observations to the cluster that is closest
Update: the cluster summaries (i.e. the mean)
Brendan demonstrated k-means clustering in action, by clustering the colours on pixals in an image on Alexandra Square, Lancaster University. We start with a single cluster (k=1) and the results look pretty grey, as the number of clusters increases the photograph becomes more identifiable. Even with 2 clusters, buildings, shadows and people are all visible since light and dark areas have been separated. By the time we hit 10 clusters, the image is starting to look similar to the original and for 100 clusters, the image is indistinguishable from the original.
k=1
k=2
k=3
k=10
k=20
k=100
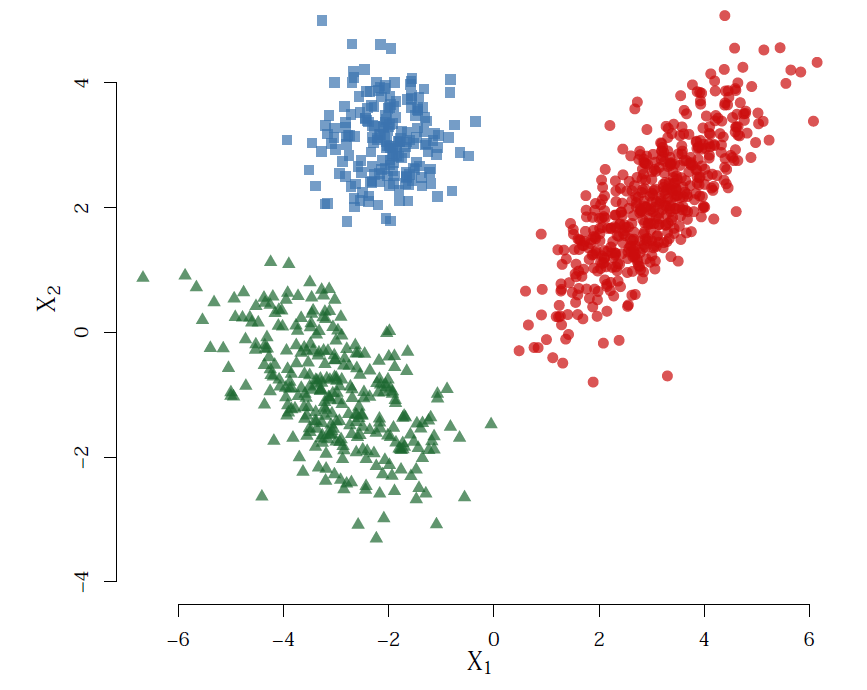
Model-Based Clustering
The first successful model-based clustering method was also developed in the 1950s by Paul Lazarsfeld for multi-variate discrete data. The model he proposed is now known as the Latent Class Model – he used the term ‘latent’ for unknown cluster allocations.
The dominant model for model-based clustering of continuous data was developed in 1963 by John Wolfe, this is known as the Gaussian Mixture Model.
Model-based clustering assumes that observations arise from a finite mixture model and that each observation has a probability that it came from each group, g – these probabilities are called the mixing proportions. The data within each group is modelled and we can combine this model, with the mixing proportions, to define an overall model for the data. Many modes of estimating these models are available, Brendan focussed on the EM algorithm.
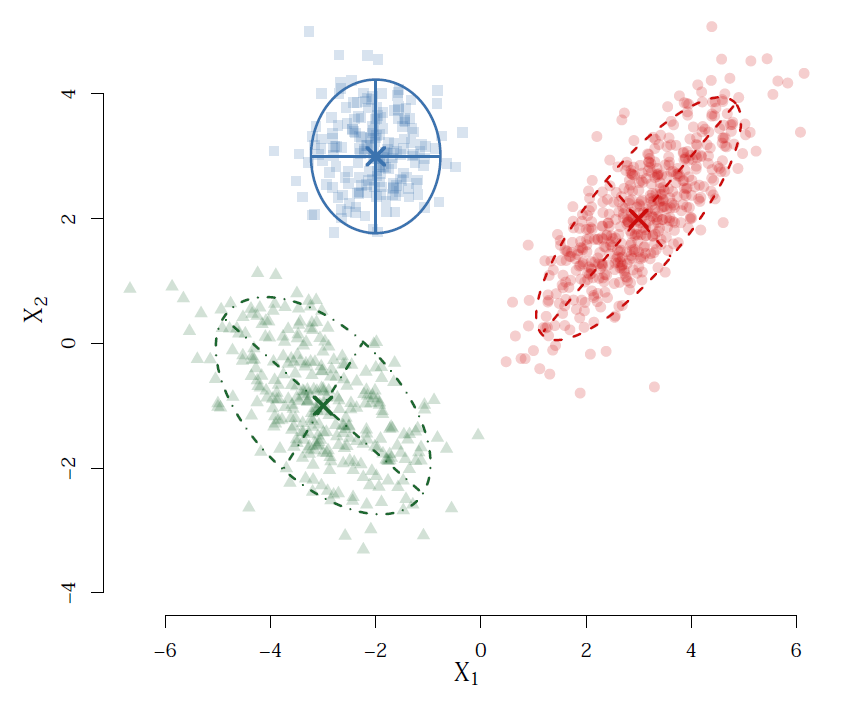
A Gaussian mixture model models each observation as a multivariate Gaussian distribution. Therefore the clusters correspond to Gaussian densities and have elliptical shapes. We use the EM algorithm to fit these Gaussian mixture models. The example below fit these clusters in just 7 iterations of the algorithm.
Further Reading
Brendan recommended some further reading:
Geoffrey McLachlan and Kaye Basford Mixture Models: Inference and Applications to Clustering
Collins, Linda M and Stephanie Lanza Latent Class and Latent Transition Analysis
Paul McNicholas Mixture Model-Based Classification
Charles Bouveyron, Gilles Celeux, Brendan Murphy and Adrian Raftery Model-Based Clustering and Classification for Data Science
Brendan is an author for the ‘mclust‘ package in R. This is used for model-based clustering, classification and density estimation based on finite Gaussian mixture-modelling fitted via the EM algorithm. This package had 1.5 million downloads in 2019!
This masterclass was my first and I really enjoyed learning about clustering and classification with Professor Brendan Murphy. I found the history, methods and applications really interesting and I am looking forward to reading further into the topic.
1 thought on “STOR-i Masterclass: Professor Brendan Murphy”







1 thought on “STOR-i Masterclass: Professor Brendan Murphy”
Comments are closed.