En los últimos meses, nuestro equipo ha sentando las bases de nuestra investigación sobre las Relaciones Geográficas y ha profundizado en el conocimiento de nuestro material original. A continuación, os mostramos un adelanto de nuestras capas SIG de topónimos que van creciendo exponencialmente.

El gran tamaño y el formato no estandarizado de las Relaciones han significado que el estudio de estos documentos se haya basado anteriormente en una lectura atenta de los textos, lo que ha limitado el alcance de la investigación. Abordar este estudio desde una perspectiva interdisciplinar nos ofrece la oportunidad de involucrarnos con metodologías computacionales innovadoras para crear nuevas oportunidades en el análisis y el estudio de estos documentos históricos, mejorando el acceso y ampliando las posibilidades de la investigación.
Algunos de los problemas clave a los que nos enfrentaremos serán: la capacidad de los métodos computacionales para tratar con corpora multilingüe, la naturaleza ambigua de muchos topónimos mencionados dentro de las Relaciones o la inaccesibilidad general de textos históricos tan amplios y complejos como éste.
Abordaremos estos problemas en colaboración como un equipo interdisciplinar, asegurando que nuestra investigación contribuya a los avances de cada uno de nuestros campos de estudio. Cada equipo aporta su propia experiencia al proyecto y, al trabajar en colaboración, estamos mejor equipados para hacer frente a los problemas que plantean materiales históricos tan extensos como las Relaciones Geográficas.
Uno de los desafíos clave a los que enfrentamos con las Relaciones Geográficas es el de la lingüística. Este corpus multilingüe presenta una combinación de español y una serie de lenguas indígenas (predominantemente náhuatl) de todas partes. El siguiente fragmento demuestra uno de los problemas lingüísticos a afrontar al tratar con estos documentos históricos: “Hun 4at” y “Oxi 4ahol” son los nombres indígenas en Quiche Maya para dos volcanes a los que se hace referencia en la Relación de Santiago Atitlán.

Con los sistemas de Procesamiento de Lenguajes Naturales generalmente entrenados con textos de noticias modernas, no podrían reconocer y etiquetar palabras en un idioma indígena como Quiche, especialmente con el uso desconocido de un carácter numérico en un topónimo. Los métodos computacionales para el análisis del lenguaje mejoran continuamente, aunque su uso en el análisis de textos históricos y no ingleses todavía presenta muchos desafíos. Nuestro proyecto tiene como objetivo abordar estos problemas y mejorar los métodos para el análisis de documentos históricos complejos, como las Relaciones Geográficas.
Déjanos tus comentarios y/o contáctanos. Si deseas leer más sobre miembros individuales de nuestro equipo, consulta nuestra página de Equipo.



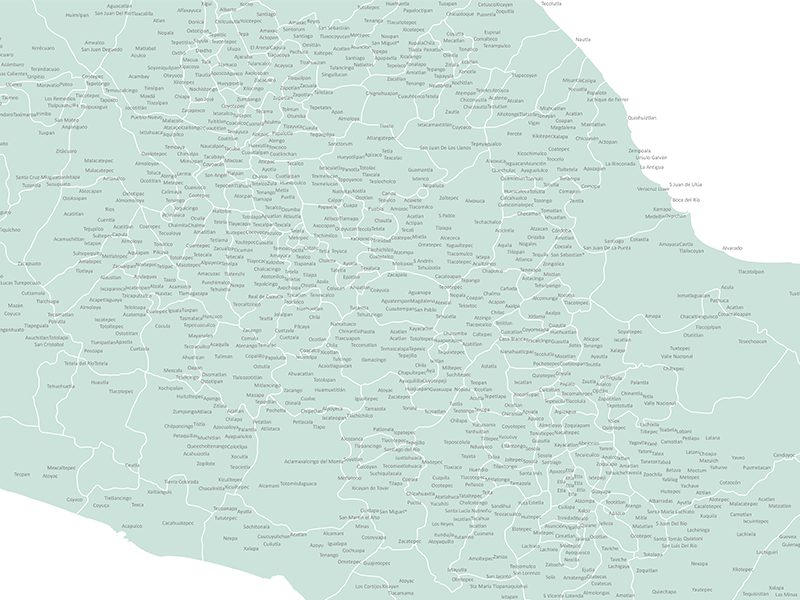
[…] nuestra última publicación, Extraer y crear datos de las Relaciones Geográficas de Nueva España, mencionamos los problemas a los que nos enfrentamos en la identificación automática de […]
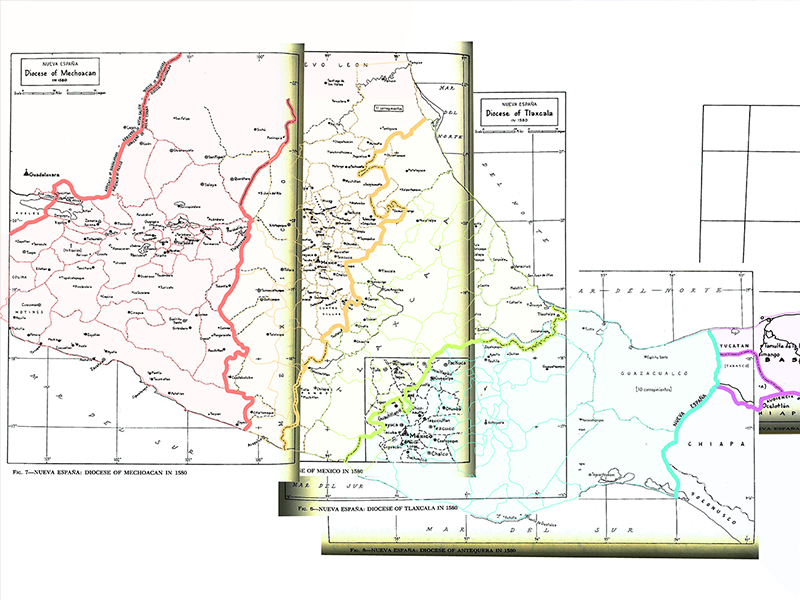
[…] y también de un sistema de información geográfica para Nueva España. Como mencionamos en una publicación anterior, nuestro corpus presenta un desafío clave para el procesamiento del lenguaje natural (NLP): […]