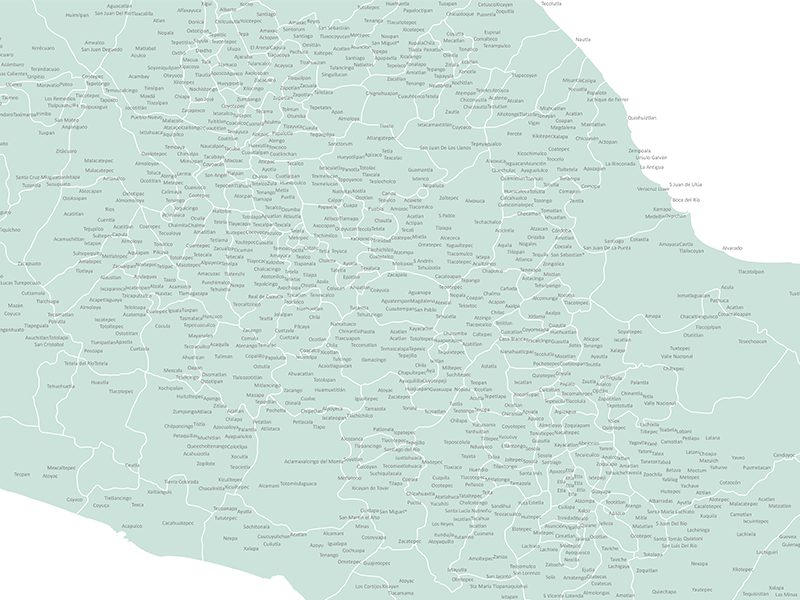
Over the past few months, our team have been laying the groundwork for our research into the Relaciones Geográficas and getting to grips with our source material. Here’s a sneak-peak of our exponentially expanding GIS place-name layers:

The sheer size and non-standardised format of the Relaciones has meant that studying these documents has previously relied on close-reading of the texts, limiting the scope of research. Approaching this study from an interdisciplinary perspective offers us the chance to engage with innovative computational methodologies to create new opportunities for the exploration and study of these historic documents, improving accessibility and broadening the scope for research.
Some of the key problems we aim to address include: the capability of computational methods in dealing with multilingual corpora, the ambiguous nature of many place-names mentioned within the Relaciones, and the general inaccessibility of historical texts as large and complex as this.
We will be tackling these problems collaboratively as an interdisciplinary team, ensuring that our research contributes to the advancements of each of our fields of study. Each team brings their own expertise to the project, and by working collaboratively we are better equipped to tackle the problems posed by large historical source materials such as the Relaciones Geográficas.
One of the key challenges we face with the Relaciones Geográficas is that of linguistics. This multilingual corpus features a combination of Spanish and a number of indigenous languages (predominantly Nahuatl) throughout. The excerpt below demonstrates one of the linguistic issues we face in dealing with these historic documents. “Hun 4at” and “Oxi 4ahol” are the indigenous names in Mayan Quiche for two volcanoes referenced in the Relación de Santiago Atitlán.

With Natural Language Processing systems usually being trained with modern news text, they would be unable to recognise and tag words in an indigenous language such as Quiche, especially with the unfamiliar usage of a numerical character in a place-name. Computational methods for the analysis of language are continually improving, though their use in the analysis of historical texts and non-English languages still presents many challenges. Our project aims to address these problems and improve methods for the analysis of complex historical documents such as the Relaciones Geográficas.
Feel free to leave your comments and/or contact us. If you would like to read more about individual members of our team, please see our Team page.


[…] our last post, Extracting and Creating Data from the Geographic Relations of New Spain, in which I mentioned the problems we face in automatized identification of place-names, I thought […]
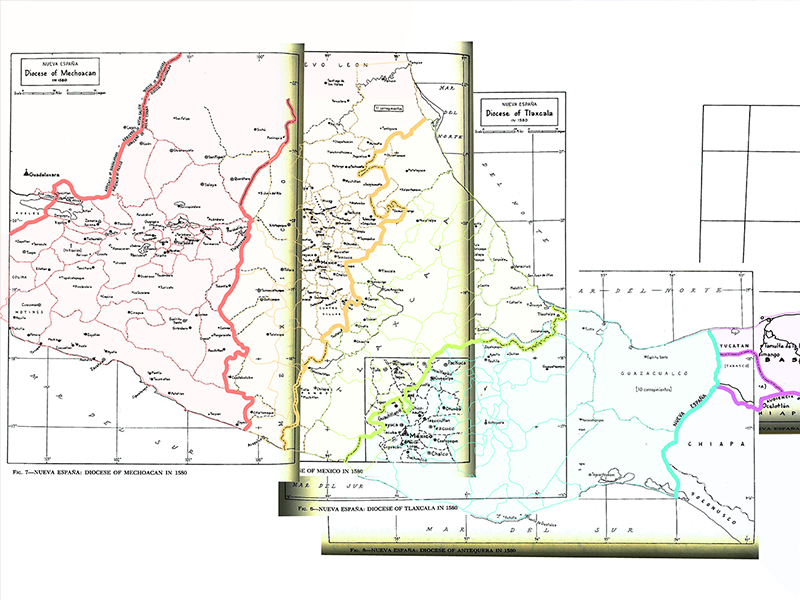
[…] as well as a comprehensive Geographic Information System of New Spain. As we have mentioned in a previous post, our corpus presents a key challenge for Natural Language Processing (NLP) – how do we accurately […]