
Jordan Kee
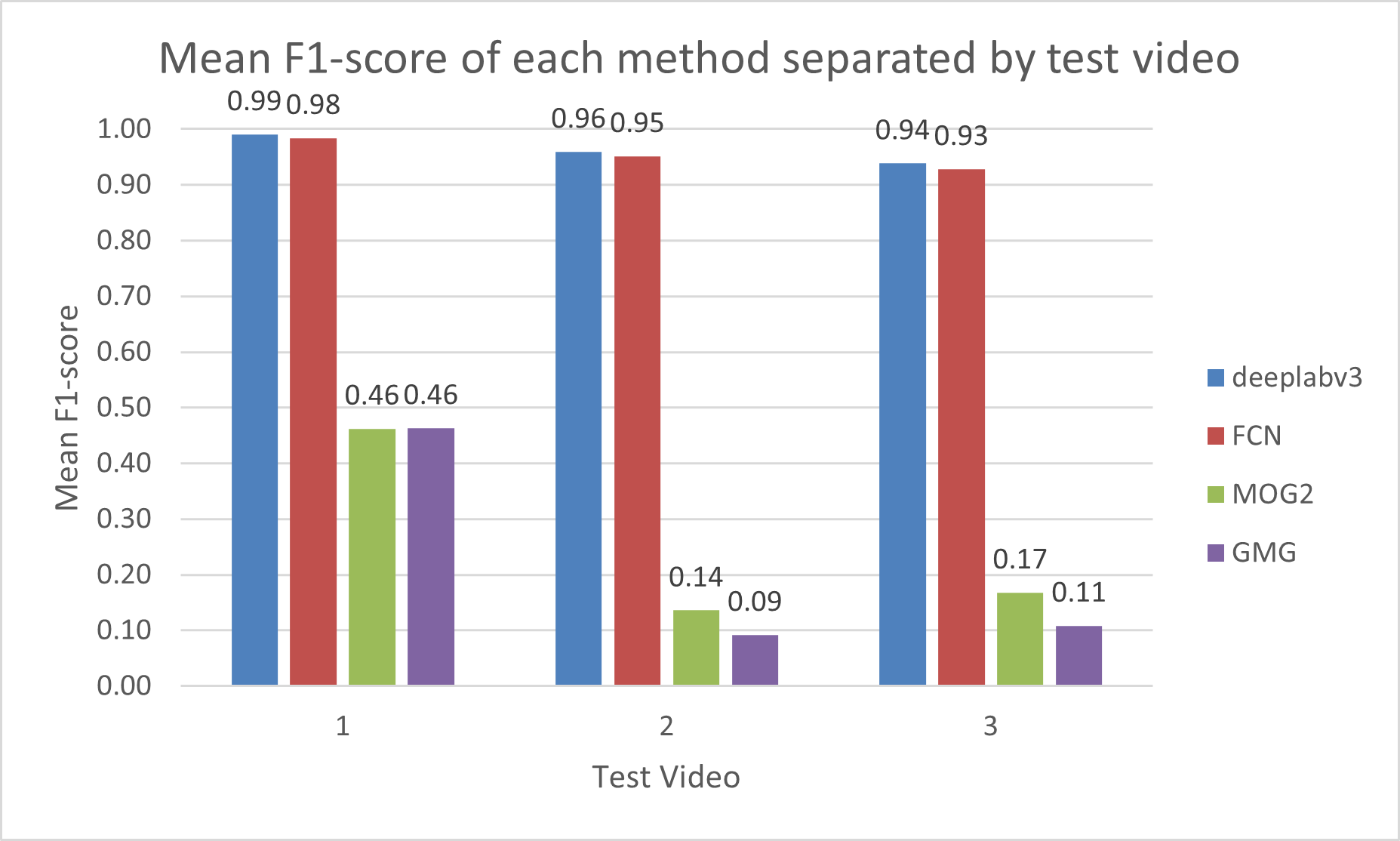
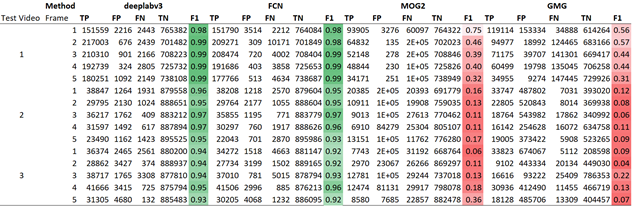
Video conferencing is commonplace nowadays. However, certain environments such as home offices may have distracting backgrounds. Silhouette extraction can remove the background from live footage without the need for a green screen which is troublesome to acquire and set-up. A test dataset was created comprising of 3 videos of differing conditions. DeepLabv3 and FCN were used to perform semantic segmentation, where the networks label each pixel of a given image with a corresponding class of what is being represented. The human category can be used to implement silhouette extraction from videos by labelling the ‘human’ tagged pixels as silhouette pixels, and everything else as background pixels. GMG and MOG2 were used to statistically model the background. Then, accuracy was derived from the confusion matrix data comparing the manually created ground truth binary maps to each method’s output.
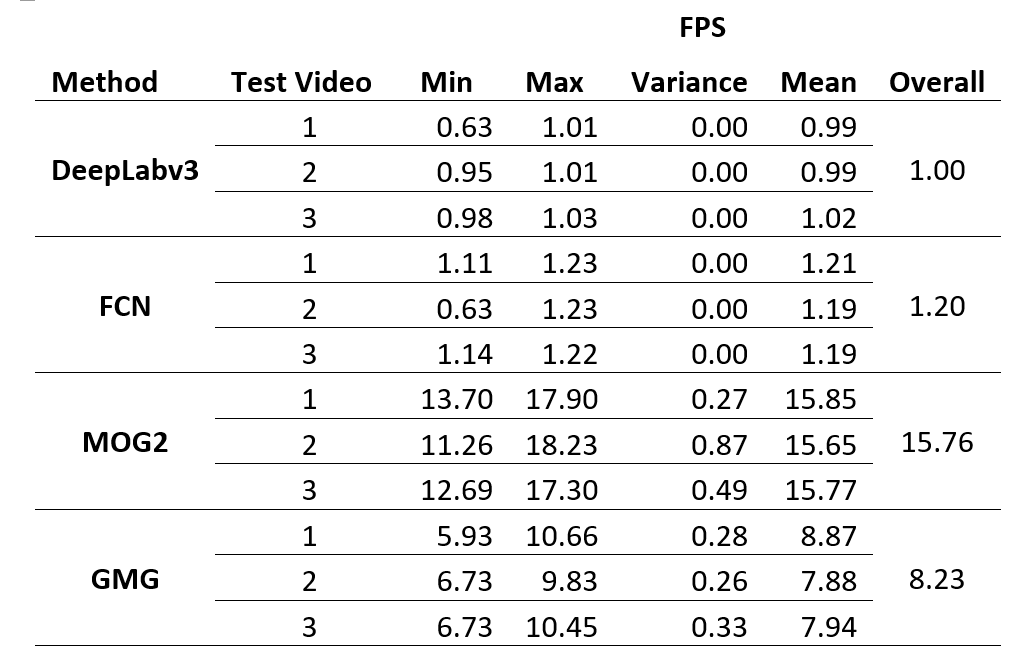
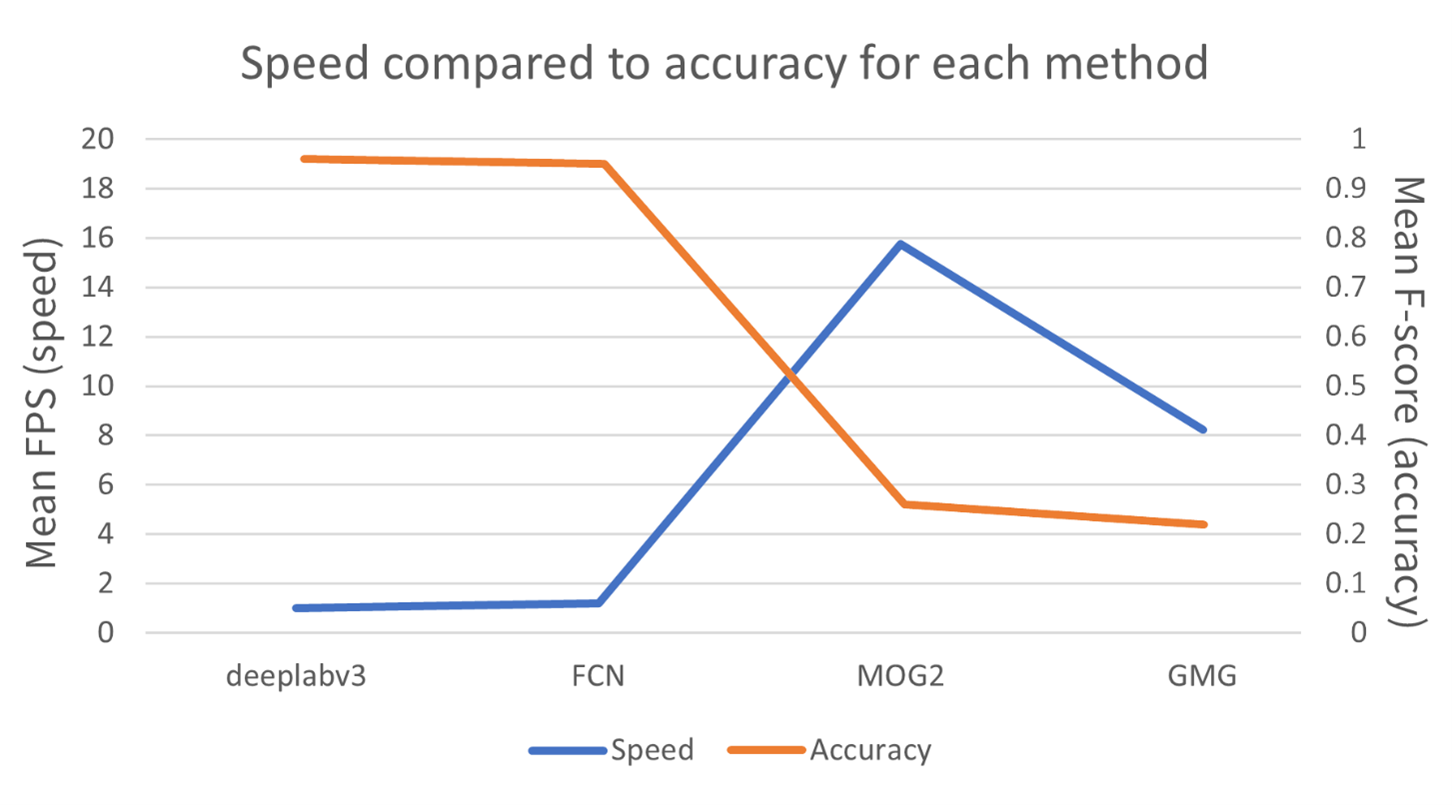
The proposed ResNet-101 based solutions using DeepLabv3 and FCN demonstrate accurate results with the overall F-score of 0.96 albeit with a significant performance penalty, running at 1.00 and 1.20 FPS compared to 15.76 and 8.23 FPS of MOG2 and GMG, respectively. A newer CNN based approach such as Faster R-CNN or Context Encoding Network (EncNet) could be explored to address the current limitations

Jordan Kee
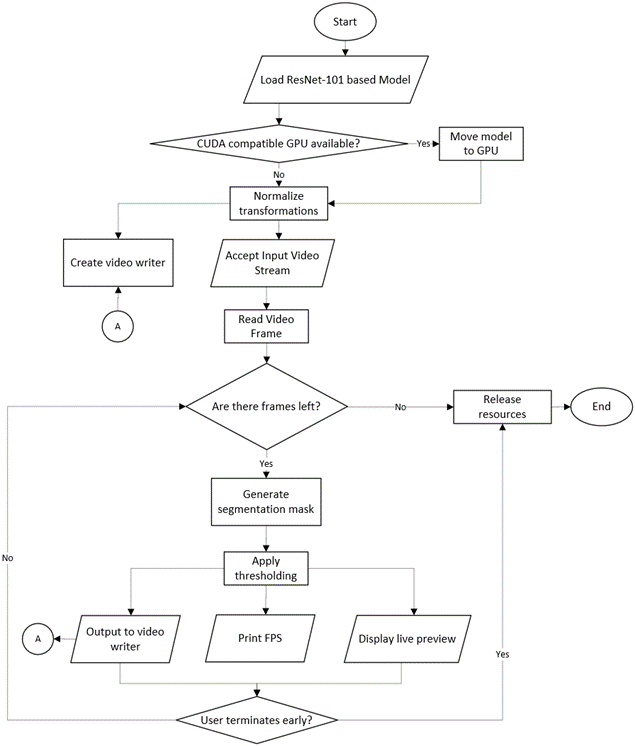

| Process | Description |
|---|---|
| Initialize background | Generate a model of the background based on a predetermined number of frames. |
| Detect foreground | For a given frame, the frame is compared with the background model generated. The comparison can be done via subtraction which would result in extracting the foreground pixels. |
| Maintain background | Based on the learning rate specified, the background model generated in the first process is updated based on the new frames observed. Usually, pixels that have not moved for a long time would be considered as part of the background and hence added to the model. |
- Only human subject(s). Preferably the same human subject for each video to achieve consistency and fair comparison. Other categories of living or non-living objects are unnecessary for the purpose of this report.
- Continuous video with no breaks. The video must have a frame rate of 30 which is commonly used in video conferencing applications. The video must contain at least 1 second of footage so that the methods tested may model the background.
- Binary map ground truth. Each video must have a corresponding binary map to act as the ground truth to perform accuracy calculations. The binary map may be selected frames at a fixed interval to reduce computational complexity as well as manpower needed for manual rotoscoping.
- Variable difficulty in the form of camera movement, background complexity, illumination changes, etc. The first video should ideally be as simple as possible to act as a best-case scenario. The various difficulties aim to test the limits of each method and find the failure cases.
| Test Video | Camera Movement | Illumination | Background Complexity | Autofocus & Autoexposure | Summary |
|---|---|---|---|---|---|
| 1 | None | Fixed | Simple and uniform | Both locked | First frame is pure background. Subject walks into frame. |
| 2 | Extreme | Fixed | Complex | Both on auto | Stimulates an extreme case of camera shake. Camera follows moving subject. |
| 3 | None | Extreme | Complex | Both on auto | Stimulates an extreme case of lighting changes. Room alternates from being illuminated with natural sunlight from windows and no lighting. |
| Function | Description |
|---|---|
| Load video | Program can accept a URL for a video stream or a file reference for a video file. |
| Capture video | Program can capture a live stream typically from a webcam. |
| Remove human silhouette | Extract only the human present in the video. |
| Live preview | Display the silhouette mask generated as well as the silhouette extracted for each frame. |
| FPS counter | Print the FPS of each frame as they are processed. |
| Save processed video | Output processed file. |








