In defining whether an observation is censored or not, we introduced indicator variables to identify whether a particular measurement arises due to censoring. This then raises the question: can the censoring indicator variables be used as an explanatory variable in a linear regression model?
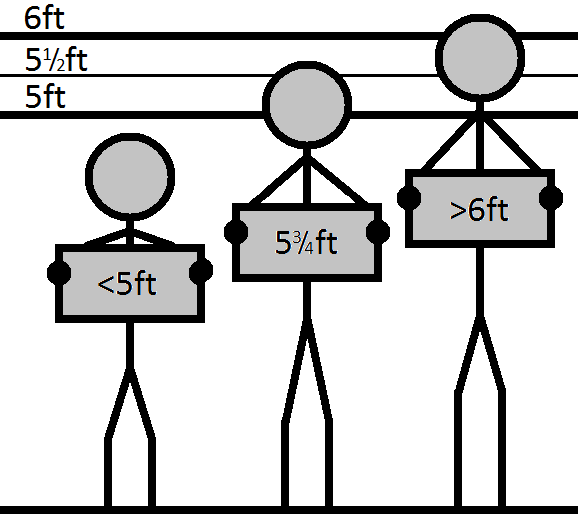
To examine this consider the prisoners data set that contains height measurements of 1000 prisoners according to the wall-chart illustrated in Figure 8.3 (Link). The data set also contains two categorical variables: the prisoner’s gender and whether the prisoner’s height was ‘O’bserved, ‘L’eft censored if they are shorter than 60 inches or ‘R’ight censored of they are taller than 72 inches.
Let denote the true height of prisoner , which we wish to model using simple linear regression model
where is a vector of explanatory variables for prisoner . However, the recorded height is restricted to the interval such that:
Here, inches is the left censoring point and inches is the right censoring point.
In the following extract, the data set prisoners is read into R and a few summaries are evaluated.
prisoners <- read.table("prisoners.dat")
range(prisoners$height)
[1] 60 72
table( prisoners$gender, prisoners$censor )
O L R
M 564 0 127
F 304 5 0
Here we see that there are 868 observed height measurements with 5 left censored events at 60 inches, all occurring for female prisoners, and 127 right censored events at 72 inches, all occurring for male prisoners.
If we then wish to use gender and the censor categorical variable as an explanatory variable in a regression model, then we can estimate the co-efficients as follows:
Model <- glm(height ~ 1 + gender + censor, data = prisoners,
family=Gaussian)
summary(Model)
Deviance Residuals:
Min 1Q Median 3Q Max
-6.502 -0.940 0.000 1.166 6.882
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 69.40877 0.06824 1017.185 < 2e-16 ***
genderF -5.21103 0.11530 -45.195 < 2e-16 ***
censorL -4.19773 0.73065 -5.745 1.22e-08 ***
censorR 2.59123 0.15917 16.280 < 2e-16 ***
---
Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
(Dispersion parameter for gaussian family taken to be 2.626082)
Null deviance: 10470.5 on 999 degrees of freedom
Residual deviance: 2615.6 on 996 degrees of freedom
Exercise 8.65
Calculate the expected height for all gender and censoring combinations. Comment on what the expected values show.
Using the censor variable in a regression model results in identifying the censoring points. Furthermore, the estimates of interest (expected height of male and female prisoners) are only derived from data that is not censored. This demonstrates the difference between identifying the best fitting model verses the usefulness of the model.
To overcome these issues, we must examine the likelihood function. Let and be indicator variables identifying whether the measurement is left or right censored respectively:
If the th prisoner’s height is observed ( and ) then the contribution to the likelihood is:
where denotes the standard normal pdf. If instead the measured height of the th prisoner is left-censored ( and ), then their true height could take any value less than . The corresponding contribution to the likelihood is:
where denotes the standard normal cdf. Finally, if the measured height of the th prisoner is instead right-censored ( and ), then their true height could take any value greater than . The corresponding contribution to the likelihood is:
Combining these components obtains the likelihood function:
It is not possible to evaluate the maximum likelihood estimates analytically, so we must adopt a numerical approach.
The glm() command in R does not allow special treatment due to censored measurements. The censReg library contains the command censReg() that fits a simple linear regression model with left, right or interval censored measurements. The arguments of this command are:
censReg( formula, left = 0, right = Inf, data, start = NULL )
formula – A symbolic description of the model to be fitted.
left – The left censoring point, taken at by default.
right – The right censoring point, taken at Inf by default.
data – A data frame containing the dependent and explanatory variables.
start – Optional starting values for the IRWLS algorithm.
Note that left censoring is defined if right=Inf, right censoring is defined if left=-Inf, or if right=Inf and left=-Inf is specified then all observations are uncensored.
For the prisoner example, we wish to model the height in terms of prisoner’s gender where the data is interval censored between 60 inches to 72 inches. This is implemented in R as follows:
library("censReg")
Model <- censReg(height ~ -1 + gender, left=60, right=72, data=prisoners)
summary(Model)
This returns:
Observations:
Total Left-censored Uncensored Right-censored
1000 5 868 127
Coefficients:
Estimate Std. error t value Pr(> t)
genderM 70.09065 0.08057 869.93 <2e-16 ***
genderF 64.11728 0.11780 544.30 <2e-16 ***
logSigma 0.72694 0.02476 29.36 <2e-16 ***
---
Signif. codes: 0 *** 0.001 ** 0.01 * 0.05 . 0.1 1
Newton-Raphson maximisation, 4 iterations
Return code 2: successive function values within tolerance limit
Log-likelihood: -2003.058 on 3 Df
Here we see that the expected height of male prisoners is 70.09 inches. This is significantly different from the previous analysis as we now utilise information of the 127 right censored heights of male prisoners. The expected height for female prisoners is slightly reduced to 64.11 inches compared to the previous analysis. In this scenario, the difference is not as pronounced as there are only 3 left censored heights of female prisoners to factor into the analysis.
{kind=link}