There are two ways of extracting information about the moments of the EF random variable . One is to calculate the cumulant generating function, the other is to investigate expectation properties of the score function. The score is the derivative of log density function with respect to the parameter. The latter is an interesting preliminary to evaluating maximum likelihood estimates.
First, the the moment generating function is
Taking logs gives the cgf
where is such that lies in . When we need to make it clear that is the cgf of then we write .
The corollary to this result are that: apart from the first, the cumulants of are given by the same function as . The mean and variance of under are given by evaluating the derivatives of the cgf evaluated at , and . Now
Furthermore
Using the properties of a cgf that and give the mean and variance, we have
The subscript denotes derivatives with respect to . We need this notation to the more usual when we change variables and need to keep track.
Exercise 3.26
Find the cgf of the Poisson distribution in terms of the
canonical parameter, and hence its mean and variance.
Recall that if is from the exponential family, then the random variable under the one-to-one transformation is also a member of the exponential family. If the transform is linear, i.e. , then we can derive the expectation and variance of from the results above:
For other non-linear transformations, however, this is not possible as expectations and functions of random variables are not commutable.
Nevertheless, using the relationship between the random variables and we can show that their moment generating functions are related by:
We can therefore define the moment generating function for the sufficient statistic by utilising our previous findings:
and too the cgf for the sufficient statistic:
Following the same argument as previously, we can therefore define the expectation and variance of as:
Exercise 3.27
For the random variable , find an expression for and .
First, define the log-likelihood function for the canonical parameter , based on a single observation , by:
Take care: the log-likelihood is also calculated as a function of the mean parameter . We are about to show that the relationship between and is invertible so that the log-likelihoods are consistent. When we need to make explicit we write .
Denote its derivatives of the log-likelihood with respect to by:
The score function is and the curvature function is .
The observed information function is .
Mean and variance of the score
In principle, both the score function and the observed information function are functions of the canonical parameter and the observation . Taking the expected value of the score function over results in:
PROOF:
The variance of the score function is:
PROOF
This is the big news! We now specialize these results to EF distributions. The log-likelihood function, the score function and the curvature function, for a single observation, are
The score is linear in and the observed information is constant with respect to . Hence the latter is identical to the Fisher or expected information.
This provides us with an alternative way to find the first two moments of . From above, the expectation of is:
and the variance of is:
A sufficient condition for a function to be strictly convex is that its second derivative be strictly positive. Hence the function is strictly convex on , because the second derivative of is which is always positive.
Consider a set of independent and identically distributed random variables from some random variable belonging to the exponential family with pmf/pdf:
The log-likelihood of the canonical parameter for all realisations is the summation of all log-likelihood contributions from each :
Taking derivatives obtains the score and curvature functions:
where and respectively denote the first and second derivatives of the function .
The maximum likelihood estimate (MLE) for the canonical parameter, , is evaluated by finding the roots of the score function:
An analytical definition of the MLE is found by deriving the inverse of the derivative function . If an analytical solution does not exist, then the MLE can be determined using a numerical algorithm such as Newton-Raphson.
The observed information for the canonical parameter evaluated at some value is
Note that the observed information for the canonical parameter of a pmf/pdf which belongs to the exponential family does not depend on the value of the realisations, but only on how many realisations there are. It follows that the expected information at is:
In many instances, the observed and expected information is evaluated at the MLE, .
Exercise 3.28
Recall that the distribution belongs to the exponential family with canonical parameter and:
Find the MLE of the canonical parameter for independent and identically distributed realisations from the Poisson distribution. Also derive an expression for the expected information at the MLE.
A central role in EF theory is played by the function that computes the moment parameter from the value of the canonical parameter .
The mean function is the mapping from to given by
The mean function is sometimes known as the mean value function. The moment parameter space is the range space of the mapping from to .
The mean function plays an important part in the theory. For example, maximum likelihood estimates of turn out to be solutions to the equation .
Exercise 3.29
Find the mean function for the Poisson distribution, in terms of the canonical parameter, and its inverse.
Exercise 3.30
Find the cgf of .
Find the mean function for the binomial distribution with generated by exponentially tilting .
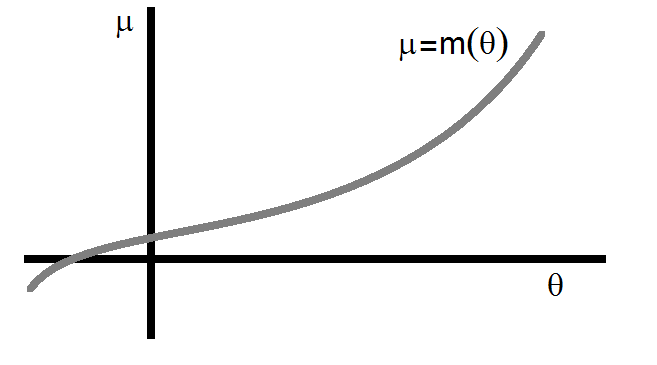
From the discussion of it follows that too, is continuous and differentiable on the interior of . The first derivative of is
so that for all . Hence is a strictly increasing function of as portrayed in the diagram.
Consequently the mapping from to is invertible. Hence there is a function going from to such that
By the inverse function rule of differentiation
The inverse mean function plays the role of the link function when the canonical parameter is chosen to be the linear predictor.
ML from a single observation
Recall that the score function based on a single observation, and obtained by differentiating the log-likelihood as a function of the canonical parameter , is
using the definition of the mean function . Hence if is a free parameter then its ML estimate satisfies
as is invertible. Finally as , ,
Equating observation with theoretical moments is a general feature of the likelihood equations in GLMs.
Exercise 3.31
Derive the MLE for the canonical parameter for a single measurement, , of a Poisson random variable.
Exercise 3.32
Find an expression for the MLE of the canonical parameter given a single observation, , from .
The relationship of the variance of to the mean of characterizes linear EF distributions. We want to compute in terms of the moment parameter .
With , the variance function, , from to the positive real line is
expressed as a function of .
This definition expresses the variance in terms of the canonical parameter . Since
Substitute for the canonical parameter in terms of to get
Exercise 3.33
Find the variance function for the Poisson distribution.
Exercise 3.34
Find the variance function for the Exponential distribution.
{kind=link}