Style control - access keys in brackets
6.4 Multiple linear regression
Multiple linear regression follows exactly the same concept as simple linear regression, except that the expected value of the response variable may depend on more than one explanatory variable.
TheoremExample 6.4.1 Birthweight cont.
As well as information on birthweight and gestational age, we know the gender of each child. This is illustrated on Figure 6.4. A separate linear relationship between birthweight and gestational age has been fitted for males and females.
-
(a)
Do males and females gain weight at different rates?
-
(b)
Do we need both gestational age and gender to explain variability in birth weights, or is one of these sufficient?
TheoremExample 6.4.2 Gas consumption cont.
A little under half way through the experiment, cavity wall insulation was installed in the house. This is illustrated in Figure 6.5. By including this information in the model, we can assess whether or not insulation alters gas consumption. In this case we might suspect that both separate intercepts and separate gradients are required for observations before insulation and after insulation.
Remark.
How can the point at which the two lines intersect be interpreted?
TheoremExample 6.4.3 Brain weight cont.
As well as brain and body weights, we also have available, for each species, total sleep (hours per day) and the period of gestation (time spent in the womb before birth, in days). Figure 6.6 suggests linear relationships between both of the variables total sleep and log gestational period and log brain weight.
- (a)
-
(b)
Are all three relationships significant?
-
(c)
Which of the three explanatory variables is the most important in explaining variability amongst brain weights?
-
(d)
How many of these explanatory variables should we use?
TheoremExample 6.4.4 Cereal prices
Regression models can be useful in economics and finance. We investigate global commodity price forecasts for various cereals from 1995–2015.
Annual prices (dollars per tonne) are available for maize, barley and wheat, made available by the Economist Intelligence Unit and downloaded from http://datamarket.com/. Figure 6.7 show maize prices against both wheat and barley prices.
-
(a)
Which of the explanatory variables best explains changes in maize prices?
-
(b)
What happens if we include both barley and wheat in the model for maize prices?
-
(c)
How well do the three possible regression models (barley only, wheat only and both barley and wheat) fit the data?
-
The multiple linear regression model has a very similar definition to the simple linear regression model, except that
-
missingi.
Each individual has a single response variable , but a missingmissingvector
of explanatory variables . The number of explanatory variables is denoted by .
-
missingi.
-
There are regression coefficients , where describes the effect of the -th explanatory variable on the expected value of the response.
Definition (Multiple linear regression model).
For ,
The residuals satisfy exactly the same assumptions as for the simple linear regression model. That is the residuals are independent and identically distributed, with a normal distribution, i.e. for ,
An informal definition of the multiple linear model is {mdframed}
-
–
, ;
-
–
are independent.
Remark.
To include an intercept term in the model, set for all individuals , gives
Then is the intercept.
Later in the course it will be useful to write our models using the following matrix notation.
-
The response vector
-
The design matrix is an matrix whose columns correspond to explanatory variables and whose rows correspond to subjects. That is denotes the value of the -th explanatory variable for individual . If an intercept term is included, then the first column of is a column of 1’s.
-
The residual vector
-
The vector of coefficients is missing
Then we can write the multiple linear regression model as follows,
-
1
where and is the identity matrix.
-
2
Informally, .
For the remainder of the course we will not distinguish between simple and multiple linear regression, since the former is a special case of the latter. Instead we refer to linear regression.
Remark.
Because of the normality assumption on the residuals the full title of the model is the normal linear regression model.
Response variables
From the informal definition of the linear regression model, the response variable should be continuous and follow a normal distribution. It only makes sense to apply a linear regression model to data for which the response variable satisfies these criteria.
The assumption of normality can be verified with a normal QQ plot. If the response if continuous and non-normal, a transformation may be used to transform to normality. For example, we might take the log or square root of the responses.
Math333 will introduce the concept of the generalised linear model, in which the normality assumption is relaxed to cover a wide family of distributions, including the Poisson and binomial.
Factors
Explanatory variables may be continuous or discrete, qualitative or quantitative.
Definition.
-
1
A covariate is a quantitative explanatory variable.
-
2
A factor is a qualitative explanatory variable. The possible values for the factor are called levels. For example, gender is a two-level factor with two levels: male and female.
Factors are represented by indicator variables in a linear regression model. For a -level factor, indicator variables are created. For individual , the indicator variable for level takes the value 1 if that individual has level of the factor; otherwise it takes the value zero.
An example of a two-level factor is gender. To include gender as an explanatory variable we create two indicator variables , to show whether individual is male, and , to show whether individual is female. Then
and
6.4.1 Examples
TheoremExample 6.4.5 Birth weights cont.
The response variable is birth weight. There are two explanatory variables, gender (factor) and gestational age (continuous). Let and be indicator variables for males and females respectively and be gestational age.
One possible model is
(6.2) This assumes a different intercept for males () and females (), but a common slope for gestational age (). It does not include an overall intercept term - we will see later why this is.
A second possible model has a common intercept, but allows for separate slopes for males and females; this is an interaction between gender and age.
(6.3) What are the interpretations of , and ?
-
1
is the expected birth weight of a baby born at 0 weeks gestation, regardless of gender;
-
2
is the expected change in birth weight for a male with every extra week of gestation;
-
3
is the expected change in birth weight for a female with every extra week of gestation.
The design matrix for model 6.2 has three columns; the first is the indicator for males, the second the indicator column for females and the third contains gestational age.
Describe the design matrix for model 6.3.
The design matrix for model 6.3 has three columns. The first is a column of 1’s for the intercept. The second is the product of the indicator variable for males and gestational age. The third is the product of the indicator variable for females and gestational age.
A third possible model, combining the first two, includes separate intercepts and separate slopes for the two genders.
(6.4) A plot of all three model fits is shown in Figure 6.8, Figure 6.9 and Figure 6.10.
Fig. 6.8: Birthweight (grams) against gestational age (weeks), split by gender. Straight lines show fit of model 6.2. Fig. 6.9: Birthweight (grams) against gestational age (weeks), split by gender. Straight lines show fit of model 6.3. Fig. 6.10: Birthweight (grams) against gestational age (weeks), split by gender. Straight lines show fit of model 6.4. Remark.
How can we choose which of models 6.2, 6.3 and 6.4 fits the data best? Intuitively model 6.3 seems sensible - all babies start at the same weight, but gender may affect the rate of growth. However, since our data only covers births from 35 weeks gestation onwards, we should only think about the model which best reflects growth during this period.
We will look at issues of model selection later.
TheoremExample 6.4.6 Gas consumption
Continuing example 6.4.2; the response is gas consumption. Two explanatory variables, outside temperature (continuous) and before/after cavity wall insulation (factor).
Let be outside temperature and be an indicator variable for after cavity wall insulation, i.e.
The modelling approach is as follows. Example 6.2.2 gave a regression on outside temperature only,
(6.5) Figure LABEL:gas_scatter2gas_scatter3 suggests that the rate of change of gas consumption with outside temperature was altered following insulation. There is also evidence of a difference in intercepts before and after insulation. We could include this information in the model as follows,
(6.6) What are the interpretations of and in this model?
-
1
is the expected gas consumption when the outside temperature is 0C, before insulation;
-
2
is the change in gas consumption for a 1C change in outside temperature, before insulation.
To interpret and :
-
1
is the expected gas consumption insulation when the outside temperature is 0C, after insulation;
-
2
is the change in gas consumption for a 1C change in outside temperature, after insulation.
tells us about the change in intercept following insulation; tells us how the relationship between gas consumption and outside temperature is altered following insulation.
Examples 6.4.5 and 6.4.6 show two different ways of including factors in linear models. In Example 6.4.5, indicator variables for all factors are included, but there is no intercept. In Example 6.4.6, there is an intercept term, but the indicator variable for only one of the two levels of the factor is included.
In general, we include an intercept term and indicator variables for levels of a -level factor. This ensures that the columns of the design matrix are linearly independent - even if we include two or more factors in the model.
For interpretation, one level of the factor is set as a ‘baseline’ (in our example this was before insulation) and the regression coefficients for the remaining levels of the factor can be used to report the additional effect of the remaining levels on top of the baseline.
6.5 Summary
{mdframed}-
1
Linear regression models provide a tool to estimate the linear relationship between one or more explanatory variables and a response variable.
-
2
Such models may be used for explanatory or predictive purposes. Care must be taken when extrapolating beyond the range of the observed data.
-
3
A simple linear regression model, which includes an intercept term and a single explanatory variable, is a special case of the multiple regression model
-
4
A number of assumptions need to be made when the model is defined:
, where the residuals are independent and identically distributed with
.
-
5
In practical terms, the response variable should be continuous with a distribution close to Normal. A transformation may be used to achieved the normality part.
-
6
Explanatory variables may be
-
1
Quantitative (covariates);
-
2
Qualitative (factors).
-
1
-
7
Factors are represented in the model using an indicator function for each level of the factor.
Chapter 7 Linear regression - fitting
The linear regression model has three unknowns:
-
1
The regression coefficients, ;
-
2
The residual variance, ;
-
3
The residuals .
In this chapter we will look at how each of these components can be estimated from a sample of data.
7.1 Estimation of regression coefficients
We shall use the method of least squares to estimate the vector of regression coefficients . For a linear regression model, this approach to parameter estimation gives the same parameter estimates as the method of maximum likelihood, which will be discussed in weeks 7–10 of this course.
The basic idea of least squares estimation idea is to find the estimate which minimises the sum of squares function
(7.1) We can rewrite the linear regression model in terms of the residuals as
By replacing with , can be interpreted as the sum of squares of the observed residuals. In general, the sum of squares function is a function of unknown parameters, . To find the parameter values which minimise the function, we calculate all first-order derivatives, set these derivatives equal to zero and solve simultaneously.
Using definition (7.1), the -th first-order derivative is
(7.2) We could solve the resulting system of equations by hand, using e.g. substitution. Since this is time consuming we instead rewrite our equations using matrix notation. The -th first-order derivative corresponds to the -th element of the vector
Thus to find we must solve the equation,
Multiplying out the brackets gives
which can be rearranged to
{mdframed}Multiplying both sides by gives the least squares estimates for ,
This is one of the most important results of the course!
Remark 1.
In order for the least squares estimate (7.3) to exist, must exist. In other words, the matrix must be non-singular,
-
1
is non-singular iff it has linearly independent columns;
-
2
This occurs iff has linearly independent columns;
-
3
Consequently, explanatory variables must be linearly independent;
-
4
This relates back to the discussion on factors in Section 6.4. Linear dependence occurs if
-
1
An intercept term and the indicator variables for all levels of a factor are include in the model; since the columns representing the indicator variables sum to the column of 1’s.
-
2
The indicator variables for all levels of two or more factors are included in a model; since the columns representing the indicator variables sum to the column of 1’s for each factor.
Consequently it is safest to include an intercept term and indicator variables for levels of each -level factor.
-
1
Remark 2.
If you want to bypass completely the summation notation used above, the sum of squares function (7.1) can be written as
(7.3) -
1
Now and since both and are scalars (can you verify this?) we have that .
-
2
Hence,
-
3
Differentiating with respect to gives the vector of first-order derivatives
as before.
Remark 3.
To prove that minimises the sum of squares function we must check that the matrix of second derivatives is positive definite at .
-
1
This is the multi-dimensional analogue to checking that the second derivative is positive at the minimum of a function in one unknown.
-
2
Returning once more to summation notation,
-
3
This is the -th element of the matrix . Thus the second derivative of is .
-
4
To prove that is positive definite, we must show that for all non-zero vectors .
-
5
Since can be written as the product of a vector and its transpose, , the result follows immediately.
7.1.1 Examples
TheoremExample 7.1.1 Birth weights cont.
We return to the birth weight data in example 6.2.1. The full data set is given in Table 7.1. We will fit the simple linear regression for birth weight with gestational age as explanatory variable,
The response vector and design matrix are
and
Obtain the least squares estimate .
To find we use the formula
From above,
-
1
-
2
-
3
Therefore,
The fitted model for birth weight, given gestational age at birth is,
We can interpret this as follows,
-
1
For every additional week of gestation, expected birth weight increases by grams.
-
2
If a child was born at zero weeks of gestation, their birth weight would be grams.
Why does the second result not make sense?
Because the matrices involved can be quite large, whether due to a large sample size , a large number of explanatory variables, or both, it is useful to be able to calculate parameter estimates using computer software. In R, we can do this ‘by hand’ (treating R as a calculator), or we can make use of the function lm which will carry out the entire model fit. We illustrate both ways.
TheoremExample 7.1.2 Birth weight model in R
Load the data set bwt into R. To obtain the size of the data set,
This tells us that there are 24 subjects and 3 variables. The variables are,
To fit the simple linear regression of the previous example ‘by hand’,
-
1
Set up the design matrix,
> X <- matrix(cbind(rep(1,24),bwt$Age),ncol=2) - 2
-
3
View results
Child Gestational Age (wks) Birth weight (grams) Gender 1 40 2968 M 2 38 2795 M 3 40 3163 M 4 35 2925 M 5 36 2625 M 6 37 2847 M 7 41 3292 M 8 40 3473 M 9 37 2628 M 10 38 3176 M 11 40 3421 M 12 38 2975 M 13 40 3317 F 14 36 2729 F 15 40 2935 F 16 38 2754 F 17 42 3210 F 18 39 2817 F 19 40 3126 F 20 37 2539 F 21 36 2412 F 22 38 2991 F 23 39 2875 F 24 40 3231 F Table 7.1: Gestational age at birth (weeks), birth weight (grams) and gender of 24 individuals. TheoremExample 7.1.3 Gas consumption cont.
Recall example 6.4.2 in which we investigated the relationship between gas consumption and external temperature. To measure the effect of changes in the external temperature on gas consumption, we fit the multiple linear regression model 6.6. We will allow a different relationship between gas consumption and outside temperature before and after the installation of cavity wall insulation. The model has four regression coefficients
Here is outside temperature and is an indicator variable taking the value 1 after installation.
The data are shown in Table 7.2.
To estimate the parameters by hand, we first set up the response vector and design matrix,
and
Since will be a matrix, it is easier to do our calculations in R. First load the data set gas.
-
1
Insulate contains Before or After to indicate whether or not cavity wall insulation has taken place;
-
2
Temp contains outside temperature;
-
3
Gas contains gas consumption;
-
4
Insulate2 contains a 0 or 1 to indicate before (0) or after (1) cavity wall insulation.
To set up the design matrix
Then to obtain ,
> beta <- solve(t(X)%*%X)%*%(t(X)%*%gas$Gas)> beta[,1][1,] 6.8538277[2,] -0.3932388[3,] -2.2632102[4,] 0.143612Thus the fitted model is
-
1
Before cavity wall insulation, when the outside temperature is 0C, the expected gas consumption is 6.85 1000’s cubic feet.
-
2
Before cavity wall insulation, for every increase in temperature of 1C, the expected gas consumption decreases by 0.393 1000’s cubic feet.
-
3
After cavity wall insulation, for every increase in temperature of 1C, the expected gas consumption decreases by 0.249 1000’s cubic feet.
Where does the figure 0.249 come from?
Substitute into the fitted model; -0.393+0.144 is the overall rate of change of gas consumption with temperature.
What is the expected gas consumption after cavity wall insulation, when the outside temperature is C?
We can alternatively fit this model in R using lm,
> gaslm <- lm(gas$Gas~gas$Temp*gas$Insulate2)> coefficients(gaslm)(Intercept) gas$Temp6.8538277 -0.3932388gas$Insulate2 gas$Temp:gas$Insulate2-2.2632102 0.143612Remark.
We have used an interaction term * between two explanatory variables. Then R includes an intercept, a term for each of the explanatory variables and the interaction between the two explanatory variables. We will look at interactions in more detail later.
Remark.
The model suggests that cavity wall insulation decreases gas consumption when the outside temperature is 0C. Further, the rate of increase in gas consumption as the outside temperature decreases is less when the cavity wall is insulated. Are these differences significant?
Observation Insulation Outside Temp. (C) Gas consumption 1 Before -0.8 7.2 2 Before -0.7 6.9 3 Before 0.4 6.4 4 Before 2.5 6.0 5 Before 2.9 5.8 6 Before 3.2 5.8 7 Before 3.6 5.6 8 Before 3.9 4.7 9 Before 4.2 5.8 10 Before 4.3 5.2 11 Before 5.4 4.9 12 Before 6.0 4.9 13 Before 6.0 4.3 14 Before 6.0 4.4 15 Before 6.2 4.5 16 Before 6.3 4.6 17 Before 6.9 3.7 18 Before 7.0 3.9 19 Before 7.4 4.2 20 Before 7.5 4.0 21 Before 7.5 3.9 22 Before 7.6 3.5 23 Before 8.0 4.0 24 Before 8.5 3.6 25 Before 9.1 3.1 26 Before 10.2 2.6 27 After -0.7 4.8 28 After 0.8 4.6 29 After 1.0 4.7 30 After 1.4 4.0 31 After 1.5 4.2 32 After 1.6 4.2 33 After 2.3 4.1 34 After 2.5 4.0 35 After 2.5 3.5 36 After 3.1 3.2 37 After 3.9 3.9 38 After 4.0 3.5 39 After 4.0 3.7 40 After 4.2 3.5 41 After 4.3 3.5 42 After 4.6 3.7 43 After 4.7 3.5 44 After 4.9 3.4 Table 7.2: Outside temperature (C), gas consumption (1000’s cubic feet) and whether or not cavity wall insulation has been installed. 7.2 Predicted values
{mdframed}Once we have estimated the regression coefficients , we can estimate predicted values of the response variable. The predicted value for individual is defined as
(7.4) This equation can also be used to obtain predicted values for combinations of explanatory variables unobserved in the sample (see example 7.2.1). However, care should be taken not to extrapolate too far outside of the observed ranges of the explanatory variables.
The predicted value is interpreted as the expected value of the response variable for a given set of explanatory variable values. Predicted values are useful for checking model fit, calculating residuals and as model output.
TheoremExample 7.2.1 Birthweights cont.
Recall the simple linear regression example on birth weights,
where is gestational age at birth. We obtained .
Can you predict the birth weight of a child at 37.5 weeks?
7.2.1 Estimation of residual variance
From the definition of the linear regression model there is one other parameter to be estimated: the residual variance . We estimate this using the variance of the estimated residuals.
The estimated residuals are defined as,
(7.5) and we estimate by
The heuristic reason for dividing by , rather than , is that although the sum is over residuals these are not independent since each is a function of the parameter estimates . Dividing by then gives an unbiased estimate of the residual variance. This is the same reason that we divide by , rather than , to get the sample variance. The square root of the residual variance, , is referred to as the residual standard error.
TheoremExample 7.2.2 Birth weights cont.
Returning to the simple linear regression on birth weight. To calculate the residuals we subtract the fitted birth weights from the observed birth weights. The birth weights are
-
1
,
-
2
,
-
3
…
What are the residuals?
The estimated residuals are
-
1
,
-
2
,
-
3
…
What is the estimate of the residual variance?
Since and ,
The estimated residuals can also be obtained from the lm fit in R,
> bwtlm$residualsSo we can calculate the residual variance as
> sum(bwtlm$residuals^2)/22Why is this estimate slightly different to the one obtained previously?
We used rounded values of to calculate the estimates. In fact, when we look at the residual standard error (), the error made by using rounded estimates is much smaller.
Finally, lm also gives the residual standard error directly, via the summary function,
> summary(bwtlm)Call:lm(formula = bwt$Weight ~ bwt$Age)Residuals:Min 1Q Median 3Q Max-262.03 -158.29 8.35 88.15 366.50Coefficients:Estimate Std. Error t value Pr(>|t|)(Intercept) -1485.0 852.6 -1.742 0.0955 .bwt$Age 115.5 22.1 5.228 3.04e-05 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 192.6 on 22 degrees of freedomMultiple R-squared: 0.554, Adjusted R-squared: 0.5338F-statistic: 27.33 on 1 and 22 DF, p-value: 3.04e-05Remark.
summary is a very useful command, for example it allows you to view the parameter estimates of a fitted model. We will use it more later in the course.
7.3 Summary
{mdframed}-
1
The regression coefficients are estimated by minimising the sum of squares function
-
2
The sum of squares function is a function of variables (the regression coefficients). To minimise this function we must calculate first-order partial derivatives, set each of these equal to zero and solve the resulting set of simultaneous equations.
-
3
The least squares estimator is given by
-
4
To estimate the residual variance, the least squares function is evaluated at and then divided by
-
5
The predicted values from a linear regression model are defined as
-
6
The predicted value is the expected (or mean) value of the response for that particular combination of explanatory variables.
Chapter 8 Sampling distribution of estimators
So far, we have focused on estimation and interpretation of the regression coefficients. In practice, it is never sufficient just to report parameter estimates, without also reporting either a standard error or confidence interval. These measures of uncertainty can also be used to decide whether or not the relationships represented by the regression models are significant.
As for the estimators discussed in Part 1, and are random variables, since they are both functions of the response vector . Consequently, they each have a sampling distribution. This is our starting point in deriving standard errors and confidence intervals.
8.1 Regression coefficients
We can write the regression coefficients as
where .
Since is considered to be fixed, is a linear combination of the random variables . By the definition of the linear model are normal random variables, and so any linear combination of is also a normal random variable (by the linearity property of the normal distribution, see Math230).
8.1.1 Expectation of least squares estimator
Find the expectation of in terms of , and .
by linearity of expectation, so by definition of linear model.
Now
where is the identity matrix. Consequently, {mdframed}
so that the estimator is unbiased.
8.1.2 Variance of least squares estimator
To find the variance,
by properties of the variance seen in Math230. By definition of linear model,
Now
Consequently, {mdframed}
To summarise, the sampling distribution for the estimator of the regression coefficient is {mdframed}
Remark.
We will see in Section 8.4 how to use this result to carry out hypothesis tests on .
Remark.
In practice, the residual variance is usually unknown and must be replaced by its estimate .
8.2 Linear combinations of regression coefficients
Recall model 6.2 for birth weight in Example 6.4.5. This model includes separate intercepts for males () and females (). We might be interested in the difference between male and female birth weights, , estimated by . In particular, we might be interested in testing whether or not there is a difference between and ,
vs.
What is an appropriate test statistic for this test? What sampling distribution should we use to obtain the critical region, -value or confidence interval? Since is a linear combination of the regression coefficients, we can find its distribution, and hence a test statistic for this test.
In general for the linear combination
then
and
Further, because follows a multivariate normal distribution, so follows a normal distribution, {mdframed}
In practice, the unknown residual variance is replaced with the estimate .
TheoremExample 8.2.1 Birth weights cont.
Recall that model 6.2 for birthweight is
where and are indicators for male and female respectively, and is gestational age. Using the data in Table 7.1, we have
What are the expectation and variance of ?
First write for some ,
So . Consequently,
and
8.3 Residual error
The sampling distribution of the estimator of the residual error follows a distribution. We do not give a formal proof of this here, but the intuition is that the estimator is the sum of squares of Normal random variables (the estimated residuals), and hence has a distribution. The degrees of freedom comes from the fact that the estimated residuals are not independent (each is a function of the estimated regression coefficients ). Additionally, in the same way that the sample mean and variance are independent, so too are the estimators of the regression coefficients and the residual variance . Although we do not prove this result, it is used below to justify an hypothesis test for the regression coefficient .
8.4 Hypothesis tests for the regression coefficients
The question that is typically asked of a regression model is ‘Is there evidence of a significant relationship between an explanatory variable and a response variable ?’. For example, ‘Is there evidence that domestic gas consumption increases as outside temperatures decrease?’
An equivalent way to ask this is ‘Is there evidence that the regression coefficient associated with the explanatory variable of interest is significantly different to zero?’ This can be answered by testing
(8.1) More generally we can test
(8.2) In analogy with the tests in Part 1, the test statistic required for the hypothesis test (8.2) is
(8.3) where is the -th diagonal element of . Since
-
1
follows a Normal distribution;
-
2
follows a distribution;
-
3
And is independent of ,
the test statistic follows a -distribution with degrees of freedom.
Note that the standard error of is .
Linear combinations of the regression coefficients
A similar approach can be taken for linear combinations of regression coefficients. From Section 8.2, we know that also has a normal distribution, with mean and variance . To test
vs.
we use a similar argument as above, comparing the test statistic
to the distribution.
The variance of can be calculated using the expression .
TheoremExample 8.4.1 Birth weights cont.
Recall the simple linear regression relating birth weight to gestational age at birth,
We want to test whether gestational age has a significant positive effect on birth weight, that is, vs. .
First, calculate . From Example 7.1.1 this is,
Now calculate the test statistic,
Compare to the distribution. From R, is 1.72. Since , we conclude that there is evidence to reject at the 5% level and say that gestational age at birth does affect birth weight.
We can use R to help us with the test. Consider again the output of the summary function
> summary(bwtlm)summary(bwtlm)Call:lm(formula = bwt$Weight ~ bwt$Age)Residuals:Min 1Q Median 3Q Max-262.03 -158.29 8.35 88.15 366.50Coefficients:Estimate Std. Error t value Pr(>|t|)(Intercept) -1485.0 852.6 -1.742 0.0955 .bwt$Age 115.5 22.1 5.228 3.04e-05 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 192.6 on 22 degrees of freedomMultiple R-squared: 0.554, Adjusted R-squared: 0.5338F-statistic: 27.33 on 1 and 22 DF, p-value: 3.04e-05Note that we can obtain the standard error of directly from the Coefficients table. In fact, we can obtain the -value for the required test, . This is clearly significant at the 5% level. However, if we want to test where , we must still calculate the test statistic by hand. For examination purposes, you will be expected to be able to calculate the test statistic using expression (8.3), so do not become too reliant on R.
TheoremExample 8.4.2 Gas consumption cont.
Recall from equation (6.6) the model relating gas consumption to outside temperature and whether or not cavity wall insulation has been installed. We fitted this model in Example 7.1.3.
-
1
Before cavity wall insulation was installed, was there a significant relationship between outside temperature and gas consumption?
-
2
After cavity wall insulation was installed, is there a significant relationship between outside temperature and gas consumption?
To answer question 1, we test
vs.
To do this, first calculate the estimated residual variance by calculating the fitted values, then the residuals and finally using expression (7.5).
Since we are testing , we need . In R,
> X <- matrix(cbind(rep(1,44),gas$Temp,gas$Insulate2,gas$Insulate2*gas$Temp),ncol=4)> solve(t(X)%*%X)[2,2][1] 0.004846722Then the test statistic is
Since and , we compare to . Clearly , so we conclude that there is evidence to reject the null hypothesis at the 5% level. i.e. there is evidence of a relationship between outside temperature and gas consumption.
We have seen that the relationship between gas consumption and outside temperature after insulation is given by . So, to answer question 2, we need to test
vs.
First, calculate the variance of . From Math230,
Next, obtain the required elements from ,
> X <- matrix(cbind(rep(1,44),gas$Temp,gas$Insulate2,gas$Insulate2*gas$Temp),ncol=4)> solve(t(X)%*%X)[2,2][1] 0.004846722> solve(t(X)%*%X)[2,4][1] -0.004846722> solve(t(X)%*%X)[4,4][1] 0.02723924and calculate the test statistic,
Finally, compare to . Since we conclude that, at the 5% level, there is evidence of a relationship between gas consumption and outside temperature, once insulation has been installed. So, the insulation has not entirely isolated the house from the effects of external temperature, but it does appear to have weakened this relationship.
8.5 Confidence intervals for the regression coefficients
We can also use the sampling distributions of and to create a confidence interval for , {mdframed}
As discussed in Part 1, the confidence interval can be used to test against . The null hypothesis is rejected at the significance level if does not lie in the confidence interval.
To test against the one-tailed alternatives,
-
1
. Calculate the confidence interval and reject at the level if lies below the lower bound of the confidence interval;
-
2
. Calculate the confidence interval and reject at the level if lies above the upper bound of the confidence interval.
TheoremExample 8.5.1 Birth weights: confidence interval and two tailed test
Derive a 95% confidence interval for the regression coefficient representing this relationship between weight and gestational age at birth.
We have all the information to do this from the previous example,
-
1
, and .
-
2
Then the 95% confidence interval for is
Since zero lies outside this interval, there is evidence at the 5% level to reject , i.e. there is evidence of a relationship between gestational age and weight at birth.
TheoremExample 8.5.2 Birth weights: confidence interval and one-tailed test
Since zero lies below the confidence interval, we might want to test
vs.
To test at the 5% level, use to calculate a 90% confidence interval and see if zero lies to the left of this confidence interval.
As above,
Since , we conclude that there is evidence for a positive relationship between gestational age and weight at birth.
8.6 Summary
{mdframed}-
1
The least squares estimator is a random variable, since it is a function of the random variable .
-
2
To obtain a sampling distribution for we write
where and so is a linear combination of normal random variables .
-
3
From this it follows that the sampling distribution is
-
4
We can use this distribution to calculate confidence intervals or conduct hypothesis tests for the regression coefficients.
-
5
The most frequent hypothesis test is to see whether or not a covariate has a ‘significant effect’ on the response variable. We can test this by testing
vs.
A one-sided alternative can be used if there is some prior belief about whether the relationship should be positive or negative.
-
6
In a similar way, a sampling distribution can be derived for linear combinations of the regression coefficients :
Chapter 9 Explanatory variables: some interesting issues
We have introduced the linear model, and discussed some properties of its estimators. Over the remaining chapters we discuss further modelling issues that can arise when fitting a linear regression model. These include
-
1
Collinearity and interactions between explanatory variables
-
2
Covariate selection (sometimes referred to as model selection)
-
3
Prediction
-
4
Diagnostics (assessing goodness of model fit to the data)
9.1 Collinearity
{mdframed}Collinearity arises when there is linear dependence (strong correlation) between two or more explanatory variables. We say that two explanatory variables and are
-
1
Orthogonal if is close to zero;
-
2
Collinear if is close to 1.
Collinearity is undesirable because it means that the matrix is ill conditioned, and inversion of is numerically unstable. It can also make results difficult to interpret.
TheoremExample 9.1.1 Cereal prices
In Example 6.4.4, we related annual maize prices, , to annual prices of barley, , and wheat, . Consider the three models:
-
1
,
-
2
,
-
3
.
We fit the models using R. First load the data set cereal, and see what it contains,
To fit the three models,
> lm1 <- lm(cereal$Maize~cereal$Barley)> lm2 <- lm(cereal$Maize~cereal$Wheat)> lm3 <- lm(cereal$Maize~cereal$Barley+cereal$Wheat)Now let’s look at the estimated coefficients in each model.
> lm1$coefficients(Intercept) cereal$Barley-9.484660 1.085748> lm2$coefficients(Intercept) cereal$Wheat-30.8254882 0.9491281> lm3$coefficients(Intercept) cereal$Barley cereal$Wheat-25.6646279 -0.5095537 1.3207563In the two covariate model, the coefficient for both Barley and Wheat are considerably different to the equivalent estimates obtained in the two one covariate models. In particular the relationship with Barley is positive in model 1 and negative in model 3. What is going on here?
To investigate, we check which of the covariates has a significant relationship with maize prices in each of the models. We will use the confidence interval method. For this we need the standard errors of the regression coefficients, which can be found by hand or using the summary function, e.g.
> summary(lm1)Call:lm(formula = cereal$Maize ~ cereal$Barley)Residuals:Min 1Q Median 3Q Max-106.401 -21.731 -5.482 21.282 89.921Coefficients:Estimate Std. Error t value Pr(>|t|)(Intercept) -9.4847 32.2742 -0.294 0.772cereal$Barley 1.0857 0.1919 5.657 1.88e-05 ***---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 45.22 on 19 degrees of freedomMultiple R-squared: 0.6274, Adjusted R-squared: 0.6078F-statistic: 32 on 1 and 19 DF, p-value: 1.875e-05so that the standard error for in model 1 is 0.1919.
For model 1, the 95% confidence interval for (barley) is
For model 2, the 95% confidence interval for (wheat) is
For model 3, the 95% confidence interval for (barley) is
and for (wheat) it is
We can conclude that
-
1
If barley alone is included, then it has a significant relationship with maize price (at the 5% level).
-
2
If wheat alone is included, then it has a significant relationship with maize price (at the 5% level).
-
3
If both barley and wheat are included, then the relationship with barley is no longer significant (at the 5% level).
Why is this?
The answer comes if we look at the relationship between barley and wheat prices, see Figure 9.1. The sample correlation between these variables is 0.939, indicating a very strong linear relationship. Since their behaviour is so closely related, we do not need both as covariates in the model.
If we do include both, then it is impossible for the model to accurately identify the individual relationships. We should use either model 1 or model 2. However, there is no statistical way to compare these two models; but one possibility is to select the one which has smallest value associated with , i.e. the one with the strongest relationship between the covariate and the response.
Fig. 9.1: Forecasts of annual prices for wheat against barley. Prices are in dollars per tonne. 9.2 Interactions
We touched on the concept of an interaction in the gas consumption model given in Example 6.4.6. In this example, the relationship between gas consumption and outside temperature was altered by the installation of cavity wall insulation. This is an interaction between a factor (insulated or not) and a covariate (temperature).
Suppose that the response variable is and there are two explanatory variables and . We could either
-
1
Model the main effects only,
-
2
Or include an interaction as well
Note the interaction term is sometimes written as .
9.2.1 Interaction between two factors
We illustrate the idea of an interaction using a thought experiment.
A clinical trial is to be carried out to investigate the effect of the doses of two drugs A and B on a medical condition. Both drugs are available at two dose levels. All four combinations of drug-dose levels will be investigated.
patients are randomly assigned to each of the possible combinations of drug-dose levels, so that patients receive each combination. The response variable is the increase from pre- to post-treatment red blood cell count. The average increase is calculated for each drug-dose level combination.
In all three outcomes, the level of both drugs affects cell count.
-
1
In outcome 1, cell count increases with dose level of both A and B. Since the size and direction of the effect of the dose level of drug A on the cell count is unchanged by changing the dose level of drug B there is no interaction.
-
2
In outcome 2, there is an interaction; at level 1 of drug B, the cell count is lower for drug A level 2, than for drug A level 1. Conversely, at level 2 of drug B, the cell count is lower for drug A level 1, than for drug A level 2. The direction of the effect of the dose levels of drug A is altered by changing the dose of drug B.
-
3
In outcome 3, there is also an interaction. In this case increasing dose level of drug A increases cell count, regardless of the level of drug B. But the difference in the response for levels 1 and 2 of drug A is much greater for level 1 of drug B than it is for level 2 of drug B. The size of the effect of the dose levels of drug A is altered by changing the dose of drug B.
9.2.2 Interaction between a factor and a covariate
Continuing with the gas consumption example. Of interest is the relationship between outside temperature and gas consumption. We saw in Figure LABEL:gas_scatter2gas_scatter3 that the size of this relationship depends on whether or not the house has cavity wall insulation and we wrote this model formally as
where
-
1
The coefficient is the size of the main effect of outside temperature on gas consumption
-
2
The coefficient is the size of the interaction between the effect of outside temperature and whether or not insulation is installed.
To test whether or not there is an interaction, i.e. whether or not installing insulation has a significant effect on the relationship between outside temperature and gas consumption, we can test
vs.
We have previously fitted this model in R,
gaslm <- lm(gas$Gas~gas$Temp*gas$Insulate2)We will use the output from this model to speed up our testing procedure,
> summary(gaslm)Coefficients:Estimate Std. Error t value Pr(>|t|)(Intercept) 6.85383 0.11362 60.320 < 2e-16 ***gas$Temp -0.39324 0.01879 -20.925 < 2e-16 ***gas$Insulate2 -2.26321 0.17278 -13.099 4.71e-16 ***gas$Temp:gas$Insulate2 0.14361 0.04455 3.224 0.00252 **---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 0.2699 on 40 degrees of freedomMultiple R-squared: 0.9359, Adjusted R-squared: 0.9311F-statistic: 194.8 on 3 and 40 DF, p-value: < 2.2e-16Find the standard error for
Reading from the second column in the Coefficients table, this is 0.04455.
Calculate the test statistic
The value of this test statistic also appears in the output above (where?) What is the critical value?
Compare to .
What do we conclude?
Since 3.22 2.021 there is evidence at the 5% level to reject , i.e. there was a significant change in the relationship between outside temperature and gas consumption following insulation.
9.3 Summary
{mdframed}-
1
Collinearity occurs when two explanatory variables are highly correlated.
-
2
Collinearity makes it hard (sometimes impossible) to disentangle the separate effects of the collinear variables on the response.
-
3
An interaction occurs when altering the value of one explanatory variable changes the effect of a second explanatory variable on the response.
-
4
This change could be a change in the size of the effect, in the direction of the effect (positive or negative), or in both of these.
Chapter 10 Covariate selection
Covariate selection refers to the process of deciding which of a number of explanatory variables best explain the variability in the response variable. You can think of it as finding the subset of explanatory variables which have the strongest relationships with the response variable.
We will only look at comparing nested models. Consider two models, the first has explanatory variables and the second has explanatory variables. We refer to the model with fewer covariates as the simpler model.
An example of a pair of nested models is when the more complicated model contains all the explanatory variables in the simpler model, and an additional explanatory variables.
For example, given a response and explanatory variables , and , we could create three possible models;
-
A
,
-
B
,
-
C
.
Which model(s) are nested inside model C?
Models A and B are nested inside model C.
Are either of models A or C nested inside model B?
Model A is, since model B is model A with an additional covariate.
Neither model B nor model C is nested in model A.
Write down another model that is nested in model C.
.
Definition (Nesting).
Define model 1 as and model 2 as , where is an matrix and is an matrix, with . Assume and are both of full rank, i.e. neither has linearly dependent columns.
Then model 1 is nested in model 2 if is a (strict) subspace of
Given a pair of nested models, we will focus on deciding whether there is enough evidence in the data in favour of the more complicated model; or whether we are justified in staying with the simpler model.
The null hypothesis in this test is always that the simpler model is the best fit.
We start with an example.
{mdframed}TheoremExample 10.0.1 Brain weights
In Section 6.2, Example 6.2.3 considered whether the body weight of a mammal could be used to predict it’s brain weight. In addition, we have the average number of hours of sleep per day for each species in the study.
Let denote brain weight, denote body weight and denote number of hours asleep per day. Here denotes species. We will model the log of both brain and body weight.
Which of the following models fits the data best?
-
1
,
-
2
,
-
3
.
There are four species for which sleep time is unknown. For a fair comparison between models, we remove these species from the following study completely, leaving observations.
We can fit each of the models in R as follows,
> L1 <- lm(log(sleep$BrainWt)~log(sleep$BodyWt))> L2 <- lm(log(sleep$BrainWt)~sleep$TotalSleep)> L3 <-lm(log(sleep$BrainWt)~log(sleep$BodyWt)+sleep$TotalSleep)Figure 10.1 shows the fitted relationships in models L1 and L2.
Fig. 10.1: Left: Right: log brain weight () against sleep per day (hours). Data for 58 species of mammals. Which of these models are nested?
Models L1 and L2 are both nested in model L3.
Using the summary function, we can obtain parameter estimates, and their standard errors, e.g.
> summary(L1)The fitted models are summarised in Table 10.1.
Model L1 2.15 (0.0991) 0.759 (0.0303) NA L2 6.17 (0.675) -0.299 (0.0588) NA L3 2.60 (0.288) 0.728 (0.0352) -0.0386 (0.0237) Table 10.1: Parameter estimates, with standard errors in brackets for each of three possible models for the mammal brain weight data. For each model, we can test to see which of the explanatory variables is significant.
For model L1, we test vs. by calculating
Comparing this to , we see that is significantly different to zero at the 5% level. We conclude that there is evidence of a significant relationship between (log) brain weight and log (body weight).
For model L2, to test vs. , calculate
Again, the critical value is . Since we conclude that there is evidence of a relationship between hours of sleep per day and (log) brain weight. This is a negative relationship: the more hours sleep per day, the lighter the brain. We cannot perhaps say that this is a causal relationship!
For model L3, we first test vs. , using
Next we test vs. , using
In both cases the critical value is ; so, at the 5% level, there is evidence of a relationship between (log) brain weight and (log) body weight, but there is no evidence of a relationship between (log) brain weight and hours of sleep per day.
To summarise, individually, both explanatory variables appear to be significant. However, when we include both in the model, only one is significant. This appears to be a contradiction. So which is the best model to explain variability amongst brain weights in mammals?
In general, we want to select the simplest possible model that explains the most variation.
Including additional explanatory variables will always increase the amount of variability explained - but is the increase sufficient to justify the additional parameter that must then be estimated?
10.1 The F test
The F-test gives a formal statistical test to choose between two nested models. It is based on a comparison between the sum of squares for each of the two models.
Suppose that model 1 has explanatory variables, model 2 has explanatory variables and model 1 is nested in model 2. Let model 1 have design matrix and parameters ; model 2 has design matrix and parameters .
First we show formally that adding additional explanatory variables will always improve model fit, by decreasing the residual sum of squares for the fitted model.
If and are the residual sums of squares for models 1 and 2 respectively. Then
Why does this last inequality hold?
Because of the nesting, we can always find a value such that
Recalling the definition of the sum of squares,
by definition of LSE. So by definition of ,
To carry out the F-test we must decide whether the difference between and is sufficiently large to merit the inclusion of the additional explanatory variables in model 2.
Consider the following hypothesis test
vs.
Remark.
We do not say that ‘Model 1 is the true model’ or ‘Model 2 is the true model’. All models, be they probabilistic or deterministic, are a simplification of real life. No model can exactly describe a real life process. But some models can describe the truth ‘better’ than others. George Box (1919-), British statistician: ‘essentially, all models are wrong, but some are useful’.
{mdframed}To test against , first calculate the test statistic
(10.1) Now compare the test statistic to the distribution, and reject if the test statistic exceeds the critical value (equivalently if the -value is too small).
The critical value from the distribution can either be evaluated in R, or obtained from statistical tables.
TheoremExample 10.1.1 Brain weights cont.
We proposed three models for log (brain weight) with the following explanatory variables:
-
1
log(body weight)
-
2
hours sleep per day
-
3
log(body weight)+hours sleep per day
Which of these models can we use the -test to decide between?
The -test does not allow us to choose between models L1 and L2, since these are not nested. However, it does give us a way to choose between either the pair L1 and L3, or the pair L2 and L3.
To choose between L1 and L2, we use a more ad hoc approach by looking to see which of the explanatory variables is ‘more significant’ than the other when we test
vs.
Using summary(L1) and summary(L2), we see that the -value for in L1 is and for in L2 is . As we saw earlier, both of these indicate highly significant relationships between the response and the explanatory variable in question.
Which of the single covariate models is preferable?
Since the -value for log(body weight) in model L1 is lower, our preferred single covariate model is L1.
We can now use the -test to choose between our preferred single covariate model L1 and the two covariate model L3,
vs.
We first find the sum of squares for both models. For L1, using the definition of the least squares,
To calculate this in R,
So .
So .
Next, we find the degrees of freedom for the two models. Since ,
-
1
L1 has regression coefficients, so the degrees of freedom are .
-
2
L3 has regression coefficients, so the degrees of freedom are .
Finally we calculate the -statistic given in equations (10.1),
The test statistic is then compared to the distribution with degrees of freedom. From tables, the critical value is just above 4.00; from R it is 4.02.
What can we conclude from this?
Since , we conclude that there is no evidence to reject . There is no evidence to choose the more complicated model and so the best fitting model is L1.
Remark.
We should not be too surprised by this result, since we have already seen that the coefficient for total sleep time is not significantly different to zero in model L3. Once we have accounted for body weight, there is no extra information in total sleep time to explain any remaining variability in brainweights.
10.1.1 Where does the F-test come from?
From Section 7.2.1, the sum of squares, divided by the degrees of freedom, is an unbiased estimator of the residual variance,
Alternatively,
So if both model 1 and model 2 fit the data then both of their normalised sums of squares are unbiased estimates of , and the expected difference in their sums of squares is,
and is also an unbiased estimator of the residual variance .
But if model 1 is not a sufficiently good model for the data
since the expected sum of squares for model 1 will be greater than as the model does not account for enough of the variability in the response.
It follows that the -statistic
is simply the ratio of two estimates of . If model 1 is a sufficient fit, this ratio will be close to 1, otherwise it will be greater than 1.
To see how far the -ratio must be from from 1 for the result not to have occurred by chance, we need its sampling distribution. It turns out that the appropriate distribution is the distribution. The proof of this is too long to cover here.
10.2 Link to one-way ANOVA
Recall from Chapter 5 that a one-way ANOVA is a method for comparing the group means of three or more groups; an extension of the unpaired -test.
It turns out that the one-way ANOVA is a special case of a simple linear model, in which the explanatory variable is a factor with three or more levels, where each level represents membership of one of the groups.
Suppose that the factor has -levels, then the linear model for a one-way ANOVA can be written as
where is the indicator variable for the -th level of the factor.
The purpose of an ANOVA is to test whether the mean response varies between different levels of the factor. This is equivalent to testing
vs.
In turn, this is equivalent to a model selection between
-
1
: Model 1, where ; and
-
2
: Model 2, where .
Now, for model 1 states that all responses share a common population mean, our design matrix is simply a column of 1’s and , the overall sample mean. For model 2, the design matrix has columns, with
Therefore is an diagonal matrix, the diagonal entries of which correspond to the number of individuals in each of the groups,
, and is a vector of length , with -th entry being the sum of all the responses in group . It follows that
i.e. the least squares estimate of the -th regression coefficient is the observed mean of that group.
Calculating the sums of squares for the two models, we have
which, in ANOVA terminology, is what we referred to has the ‘total sum of squares’, and
which, in ANOVA terminology, is what we referred to as the within groups sum of squares.
Consequently, the -ratio for model selection can be shown to be identical to the test statistic used for the one-way ANOVA:
10.3 Summary
{mdframed}-
1
Covariate selection is the process of deciding which covariates explain a significant amount of the variability in the response.
-
2
Two nested linear regression models can be compared using an -test. Take two models
-
1
,
-
2
,
where and have the same number of rows, but the number of columns in is less than that in . Provided and are of full rank, then the first model is nested in the second if is a subspace of .
-
1
-
3
A simple example of nesting is when the more complicated model contains all the explanatory variables in the first model, plus one or more additional ones.
-
4
Introducing extra explanatory variables will always reduce the residual sum of squares.
-
5
To compare two nested models with sums of squares (simpler model) and (more complicated model), calculate
and compare this to the distribution.
-
6
The one-way ANOVA can be shown to be a special case of the multiple linear regression model, in which all the explanatory variables are taken to be indicator functions denoting membership of each of the groups.
Chapter 11 Diagnostics
Even if a valid statistical method, such as the -test, has been used to select our preferred linear model, checks should still be made to ensure that this model fits the data well. After all, it could be that all the models that we tried to fit actually described the data poorly, so that we have just made the best of a bad job. If this is the case, we need to go back and think about the underlying physical processes generating the data to suggest a better model.
Diagnostics refers to a set of tools which can be used to check how well the model describes (or fits) the data. We will use diagnostics to check that
-
1
The estimated residuals follow a distribution;
-
2
The estimated residuals are independent of the covariates used in the model;
-
3
The estimated residuals are independent of the fitted values ; None of the observations is an outlier (perhaps due to measurement error);
-
4
No observation has undue influence on the estimated model parameters.
11.1 Normality of residuals
One of the key underlying assumptions of the linear regression model is that the errors have a Normal distribution. In reality, we do not know the errors and these are replaced with their estimates, . We compare these estimated residuals to their model distribution using graphical diagnostics:
{mdframed}PP (probability-probability) and QQ plots can be used to check whether or not a sample of data can be considered to be a sample from a statistical model (usually a probability distribution). In the case of the normal linear regression model, they can be used to check whether or not the estimated residuals are a sample from a distribution. PP plots show the same information as QQ plots, but on a different scale.
{mdframed}The PP plot is most useful for checking that values around the average (the body) fit the proposed distribution. It compares the percentiles of the sample of data, predicted under the proposed model, to the percentiles obtained for a sample of the same size, predicted from the empirical distribution
The QQ plot is most useful for checking whether the largest and smallest values (the tails) fit the proposed distribution. It compares the ordered sample of data to the quantiles obtained for a sample of the same size from the proposed model.
First define the standardised residuals to be
From Math230, standardising by means that these should be a sample from a distribution.
Denote by the ordered standardised residuals, so that is the smallest residual, and the largest. We compare the standardised residuals to the standard normal distribution, using
-
1
A PP plot,
for . Here is the standard normal cumulative distribution function.
-
2
A QQ plot,
for , where is the inverse of the standard normal cumulative distribution function.
If the standardised residuals follow a distribution perfectly, both plots lie on the line . Because of random variation, even if the model is a good fit, the points won’t lie exactly on this line.
Remark.
You have seen QQ plots before in Math104; in that setting, they were used to examine whether data could be considered to be a sample from a Normal distribution.
TheoremExample 11.1.1 Brain weights cont.
In example 10.1.1 we fitted the following linear regression model to try to explain variability in (log) brain weight () using (log) body weight (),
We use R to create PP and QQ plots for the standardised residuals. First we will refit the model in R to obtain the required residuals,
> L1 <- lm(log(sleep$BrainWt)~log(sleep$BodyWt))Next we need the residual variance,
> sigmasq <- sum(L1$resid^2)/56and we can use this to get the standardised residuals:
> stdresid <- L1$residuals/sqrt(sigmasq)R does not have an inbuilt function for creating a PP plot, but we can create one using the function qqplot,
> qqplot(c(1:58)/59,pnorm(stdresid),xlab="Theoretical probabilities",ylab="Sample probabilities")> abline(a=0,b=1)Since we are comparing the standardised residuals to the standard Normal distribution, we can use the function qqnorm for the QQ plot,
Fig. 11.1: PP plot for standardised residuals from model for log Brain weight (). Straight lines show exact agreement between the residuals and a Normal(0,1) distribution. Fig. 11.2: QQ plot for standardised residuals from model for log Brain weight (). Straight lines show exact agreement between the residuals and a Normal(0,1) distribution. Remark.
In general, a QQ plot is more useful that a PP plot, as it tells us about the more ‘unusual’ values (i.e. the very high and very low residuals). It is the behaviour of these values which is most likely to highlight a lack of model fit.
Remark.
If the PP and QQ plots suggest that the residuals differ from the distribution in a systematic way, for example the points curve up (or down) and away from the 45 line at either (or both) of the tails, it may be more appropriate to
-
1
Transform your response, e.g. use the log or square root functions, before fitting the model; or
-
2
Use a different residual distribution. This is discussed in Math333 Statistical Models.
Remark.
A lack of normality might also be due to the residuals having non-constant variance, referred to as heteroscedasticity. This can be assessed by plotting the residuals against the explanatory variables included in the model to see whether there is evidence of variability increasing, or decreasing, with the value of the explanatory variable.
11.2 Residuals vs. Fitted values
A further implication of the assumptions made in defining the linear regression model is that the residuals are independent of the fitted values . This can be proved as follows:
Recall the model assumption that
Then the fitted values and estimated residuals are defined as
(11.1) and
(11.2) where we define
Remark.
Since both and are both functions of the random variable , they are themselves random variables. This means that they have sampling distributions. We focus on the joint behaviour of the two random variables.
To show that the fitted values and estimated residuals are independent, we show that the vectors and are orthogonal, i.e. that they have a product of zero.
By definition of and ,
since . So .
This result uses the identities and . Starting from the definition of can you prove these identities? Now you should be able to show, by combining these identities, that is idempotent, i.e. that .
Since is idempotent, when applied to its image, the image remains unchanged. In other words, maps to itself. Can you show this? Mathematically, can also be thought of as a projection. The matrix is often referred to as the hat matrix, since it transforms the observations to the fitted values .
A sensible diagnostic to check the model fit is to plot the residuals against the fitted values and check that these appear to be independent:
TheoremExample 11.2.1 Brain weights cont.
For the fitted brain weight regression model described in example (11.1.1), a plot of the residuals against the fitted values is shown in Figure 11.3. The code used in R to produce this plot is
> plot(L1$fitted.values,L1$residuals,xlab="Fitted",ylab="Residuals")> R <- lm(L1$residuals~L1$fitted.values)> abline(a=R$coefficients[1],b=R$coefficients[2])The horizontal line indicates the line of best fit through the scatter plot. The correlation between the fitted values and residuals is
In this case, there is clearly no linear relationship between the residuals and fitted values and so, by this criterion, the model is a good fit.
Fig. 11.3: Residual vs. fitted values for the brain weight model. Straight lines show linear relationships, which is negligible. 11.3 Residuals vs. Explanatory variables
For a well fitting model the residuals and the explanatory variables should also be independent. We can again prove this easily, by showing that the vector of estimated residuals is independent of each of the explanatory variables. In other words, each column of the design matrix X is orthogonal to the vector of estimated residuals .
Therefore, we need to show that
Using the definition of the vector of estimated residuals in (11.2)),
The penultimate step uses the result , since, on substitution of the definition of ,
TheoremExample 11.3.1 Brain weights cont.
Figure 11.4 also shows a plot of the residuals from the fitted brain weight regression model in example (11.1.1) against the explanatory variable, the log of body weight. The code to produce this plot is
plot(log(sleep$BodyWt),L1$residuals,xlab="log(Body Weight)",ylab="Residuals")R <- lm(L1$residuals~log(sleep$BodyWt))abline(a=R$coefficients[1],b=R$coefficients[2])Fig. 11.4: Residual vs. explanatory variable for the brain weight model. Straight lines show linear relationships, which is negligible. The horizontal line is the line of best fit through the scatter plot, again indicating to linear relationship between the explanatory variable and the residuals. This is verified by a correlation of .
11.4 Outliers
An outlier is an observed response which does not seem to fit in with the general pattern of the other responses. Outliers may be identified using
-
1
A simple plot of the response against the explanatory variable;
-
2
Looking for unusually large residuals;
-
3
Calculating studentized residuals.
The studentized residual for observation is defined as
where is the -th element on the diagonal of the hat matrix . The term comes from the sampling distribution of the estimated residuals, the derivation of which is left as a workshop question.
Remark.
The diagonal terms are referred to as the leverages. This name comes about since, as gets closer to one, so the fitted value gets closer to the observed value . That is an observation with a large leverage will have a considerable influence on its fitted value, and consequently on the model fit.
We can test directly the null hypothesis
vs.
by calculating the test statistic
This is compared to the -distribution with degrees of freedom. We test assuming a two-tailed alternative. If the test is significant, there is evidence that observation is an outlier.
An alternative definition of is based on fitting the regression model, without using observation . This model is then used to predict the observation , and the difference between the observed and predicted values is calculated. If this difference is small, the observation is unlikely to be an outlier as it can be predicted well using only information from the model and the remaining data.
The above discussions focus on identifying outliers, but don’t specify what should be done with them. In practice, we should attempt to find out why the observation is an outlier. This reason will indicate whether the observation can safely be ignored (e.g. it occurred due to measurement error) or whether some additional term should be included in the model to explain it.
TheoremExample 11.4.1 Atmospheric pressure
Weisberg (2005), p.4 presents data from an experiment by the physicist James D. Forbes (1857) on the relationship between atmospheric pressure and the temperature at which water boils. The 17 observations, and fitted linear regression model, are plotted in Figure 11.5.
Fig. 11.5: Atmospheric pressure against the boiling point of water, with fitted line . Are any of the observations outliers?
A plot of the residuals against temperature in Figure 11.6, suggests that observation 12 might be an outlier, since its residual is much larger than the rest ().
Fig. 11.6: Residuals from the fitted model against temperature. To calculate the standardized residuals, we first set up the design matrix and calculate the hat matrix ,
> load("pressures.Rdata")> n <- length(pressure$Temp)> X <- matrix(cbind(rep(1,n),pressure$Temp),ncol=2)> H <- X%*%solve(t(X)%*%X)%*%t(X)> H[12,12][1] 0.06393448We also need the residual variance
From the summary command we see that the estimated residual standard error is 0.2328. Similarly
> L$residuals[12]gives the residual .
Combining these results, the studentized residual is
Since and , the test statistic is
The -value to test whether or not observation 12 is an outlier is then
> 2*(1-pt(4.18,df=14))which is . Since this is extremely small, we conclude that there is evidence that observation 12 is an outlier.
11.5 Influence
Outliers can have an unduly large influence on the model fit, but this is not necessarily the case. Conversely, some points which are not outliers may actually have a disproportionate influence on the model fit. One way to measure the influence of an observation on the overall model fit is to refit this model without the observation.
Cook’s distance summarises the difference between the parameter vector estimated using the full data set and the parameter vector obtained using all the data except observation .
The formula for calculating Cook’s distance for observation is
where is the studentized residual.
It is not straightforward to derive the sampling distribution for this test statistic. Instead it is common practice to follow the following guidelines.
-
1
First, look for observations with large , since if these observations are removed, the estimates of the model parameters will change considerably.
-
2
If is considerably less than 1 for all observations, none of the cases have an unduly large influence on the parameter estimates.
-
3
For every influential observation identified, the model should be refitted without this observation and the changes to the model noted.
TheoremExample 11.5.1 Atmospheric pressure cont.
We calculate Cook’s distance for the outlying observation (number 12). From the previous example , and . Therefore,
Since this is reasonably far from 1, we conclude that whilst observation 12 is an outlier, it does not appear to have an unduly large influence on the parameter estimates.
11.6 Diagnostics in R
As with everything else we have covered relating to the linear model, model diagnostics can easily be calculated in R. If we consider again the pressure data used in the last two examples. Start by fitting the linear model
> L <- lm(pressure$Pressure~pressure$Temp)If we apply the base plot function to a lm fit, we can obtain a total of six possible diagnostic plots. We shall look at four of these: residuals against fitted, a normal QQ plot of the residuals, Cook’s distances and square root of the standardised residuals against the fitted values, and standardised residuals against leverage.
The results can be seen in Figure 11.7.
-
1
For the first plot, we expect to see no pattern, since residuals and fitted values should be independent. The red line indicates any trend in the plot.
-
2
For the QQ plot we hope to see points lying on the line , indicated by the dotted line.
-
3
For the Cook’s distance plot we are looking for any particularly large values. The observation number for these will be given (in this example 12, 2 and 17).
-
4
For the residuals vs. leverage plot we are looking for any points that have either (or both) an unusually large leverage or an unusually large residual. The red dashed lines show contours of equal Cook’s distance.
Fig. 11.7: Diagnostics for the pressure temperature regression model. An alternative is to download and install the car package, as this has many functions for regression diagnostics. For example
produces a bubble plot of the Studentised residuals against the hat values . The bubbles are proportional to the size of Cook’s distance. In the pressure data example (see Figure 11.8) we can see that observation 12 is a clear outlier. In addition this function prints values of Cook’s distance, the hat value and the Studentised residual for any ‘unusual’ observations.
Fig. 11.8: Hat values, studentised residuals and Cooks distance for the pressure temperature regression model. The sizes of the bubbles are proportional to Cook’s distance. 11.7 Summary
{mdframed}-
1
Even though you have selected a best model using appropriate covariate selection techniques, it is still necessary to check that the model fits well. Diagnostics provide us with a set of tools to do this.
-
2
Diagnostics check that key assumptions made when fitting the linear regression model are in fact satisfied.
-
3
QQ and PP plots can be used to check that the estimated residuals are approximately normally distributed.
-
4
Plots of estimated residuals vs. fitted values, and estimated residuals vs. explanatory variables, should also be made, to check that these are independent.
-
5
The hat matrix
can be used to prove independence of estimated residuals and fitted values, and of estimated residuals and explanatory variables.
-
6
In addition the data should be checked for outliers and points of strong influence.
-
1
Outlier: a data point which is unusual compared to the rest of the sample. It usually has a very large studentised residual.
-
2
Influential observation: makes a larger than expected contribution to the estimate of . It will have a large value of Cook’s distance.
-
1
Chapter 12 Introduction to Likelihood Inference
12.1 Motivation
TheoremExample 12.1.1 London homicides

A starting point is typically a subject-matter question.
Four homicides were observed in London on 10 July 2008.
Is this figure a cause for concern? In other words, is it abnormally high, suggesting a particular problem on that day?
We next need data to answer our question. This may be existing data, or we may need to collect it ourselves.
We look at the number of homicides occurring each day in London, from April 2004 to March 2007 (this just happens to be the range of data available, and makes for a sensible comparison). The data are given in the table below.
No. of homicides per day 0 1 2 3 4 Observed frequency 713 299 66 16 1 0 Table 12.1: Number of homicides per day over a 3 year period. Before we go any further, the next stage is always to look at the data through exploratory analysis.
> obsdata<-c(713,299,66,16,1,0)> barplot(obsdata,names.arg=0:5,xlab="Number of homicides", ylab="Frequency",col="blue")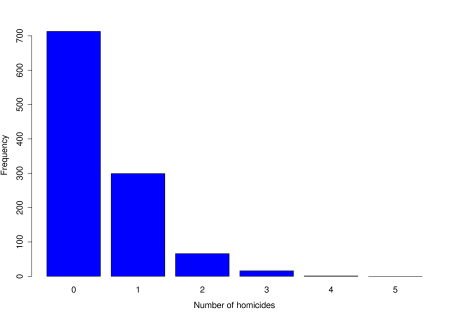
Next, we propose a model for the data to begin addressing the question.
It is proposed to model the data as iid (independent and identically distributed) draws from a Poisson distribution.
Why is this a suitable model?
What assumptions are being made?
Are these assumptions reasonable?
The probability mass function (pmf) for the poisson distribution is given by
for , so it still remains to make a sensible choice for the parameter . As before, we will make an estimate of based on our data; the equation we use to produce the estimate will be a different estimator than in Part 1.
12.2 What is likelihood?
In the last example we discussed that a model for observed data typically has unknown parameters that we need to estimate. We proposed to model the London homicide data by a Poisson distribution. How do we estimate the parameter? In Math104 you met the method of moments estimator (MOME); whilst it is often easy to compute, the estimators it yields can often be improved upon; for this reason it has mostly been superceded by the method of maximum likelihood.
Definition.
Suppose we have data , that arise from a population with pmf (or pdf) , with at least one unknown parameter . Then the likelihood function of the parameter is the probability (or density) of the observed data for given values of .
If the data are iid, the likelihood function is defined as
The product arises because we assume independence, and joint probabilities (or densities) obey a product law under independence (Math230).
TheoremExample 12.2.1 London homicides continued
For the Poisson example, recall that the probability mass function (pmf) for the Poisson distribution is given by
We will always keep things general to begin by talking in terms of data , rather than the actual data from the table. From the above definition, the likelihood function of the unknown parameter is
Let’s have a look at how the likelihood function behaves for different values of . To keep things simple, let’s take just a random sample of 20 days.
set.seed(1)#read in the datax<-c(rep(0,713),rep(1,299),rep(2,66),rep(3,16),4)%\end{lstlisting}\begin{lstlisting}#take a sample: 20 observationsxs<-sample(x,20)#likelihood functionL<-function(lam){m<-length(lam)sapply(1:m, function(i) prod(dpois(xs,lam[i])))}#values of lambda to plot (trial and error..)lam<-seq(from=0.3,to=1.1,length=100)plot(lam,L(lam),type="l")
What does the likelihood plot tell us?
Definition.
Maximum likelihood estimator/estimate. For given data , the maximum likelihood estimate (MLE) of is the value of that maximises , and is denoted . The maximum likelihood estimator of based on random variables will be denoted .
So the MLE, , is the value of where the likelihood is the largest. This is intuitively sensible.
It is often computationally more convenient to take logs of the likelihood function.
Definition.
The log-likelihood function is the natural logarithm of the likelihood function and, for iid data is denoted thus:
One reason that this is a good thing to do is it means we can switch the product to a sum, which is easier to deal with algebraically.
IMPORTANT FACT: Since ‘log’ is a monotone increasing function, maximises the log-likelihood if and only if it maximises the likelihood; if we want to find an MLE we can choose which of these functions to try and maximise.
Let us return to the Poisson model. The log-likelihood function for the Poisson data is
We can now use the maximisation procedure of our choice to find the MLE. A sensible approach in this case is differentiation.
Now if we solve , this gives us potential candidate(s) for the MLE. For the above, there is only one solution:
i.e.
To confirm that this really is the MLE, we need to verify it is a maximum:
It is clear intuitively that this is a sensible estimator; let’s formalise that into two desirable features we may look for in a ‘good’ estimator. We recall these properties (which you have met before):
Now plugging in the value of we find that
Plugging in the actual numerical values of the data at the last minute is good practice, as it means we have solved a more general problem, and helps us to remember about sampling variation.
The next step is to check that the Poisson model gives a reasonable fit to the data.
Plotting the observed data against the expected data under the assumed model is a useful technique here.
> #value of lambda from mom> momlam<-483/1095> #expected data counts> expdata<-1095*dpois(0:5,momlam)> #make plot> barplot(rbind(obsdata,expdata),names.arg=0:5,xlab="Number of homicides",ylab="Frequency"col=c("blue","green"),beside=T)> #add legend> legend("topright",c("observed","expected"),col=c("blue","green"),lty=1)
The fit looks very good!
Let us now compare this to another estimator you already know: the method of moments estimator from Math104.
Definition.
Let be an iid sample from pmf or pdf , where is one-dimensional. Then the method of moments estimator (MOME) solves
The left hand side is the theoretical moment and the right hand side is the sample moment. What this means is that we should choose the value of such that the sample mean is equal to the theoretical mean.
In our example, recall that for a Poisson distributed random variable, . Therefore the MOME for is
Notice that the MLE coincides with the MOME. We should be glad it does in this case, because the estimator is clearly sensible!
Whenever the MOME and MLE disagree, the MLE is to be preferred. Much of the rest of this part of the course sets out why that is the case.
Finally, we need to provide an answer to the original question.
Four homicides were observed in London on 10 July 2008. Is this figure a cause for concern?
The probability, on a given day, of seeing four or more homicides under the assumed model, where , is given by
by Math230 or R.
But what must be borne in mind is that we can say this about any day of the year.
Assuming days are independent (which we did anyway when fitting the Poisson distribution earlier), if is the number of times we see 4 or more homicides in a year, then , and
So there is a chance of approximately that we see 4 or more homicides on at least one day in a given year.
Some R code for the above:
12.3 Likelihood Examples: continuous parameters
We now explore examples of likelihood inference for some common models.
TheoremExample 12.3.1 Accident and Emergency
Accident and emergency departments are hard to manage because patients arrive at random (they are unscheduled). Some patients may need to be seen urgently.

Excess staff (doctors and nurses) must be avoided because this wastes NHS money; however, A&E departments also have to adhere to performance targets (e.g. patients dealt with within four hours). So staff levels need to be ‘balanced’ so that there are sufficient staff to meet targets but not too many so that money is not wasted.
A first step in achieving this is to study data on patient arrival times. It is proposed that we model the time between patient arrivals as iid realisations from an Exponential distribution.
Why is this a suitable model?
What assumptions are being made?
Are these assumptions reasonable?
Suppose I stand outside Lancaster Royal Infirmary A&E and record the following inter-arrival times of patients (in minutes):
18.39, 2.70, 5.42, 0.99, 5.42, 31.97, 2.96, 5.28, 8.51, 10.90.
As usual, the first thing we do is look at the data!
arrive<-c(18.39,2.70,5.42,0.99,5.42,31.97,2.96,5.28,8.51,10.90)stripchart(arrive,pch=4,xlab="inter-arrival time (mins)")
The exponential pdf is given by
for , . Assuming that the data are iid, the definition of the likelihood function for gives us, for general data ,
Note: we usually drop the ‘’ from whenever possible.
Usually, when we have products and the parameter is continuous, the best way to find the MLE is to find the log-likelihood and differentiate.
So the log-likelihood is
Now we differentiate:
Now solutions to are potential MLEs.
-
1
-
2
To ensure this is a maximum we check the second derivative is negative:
So the solution we have found is the MLE, and plugging in our data we find (via 1/mean(arrive))
Now that we have our MLE, we should check that the assumed model seems reasonable. Here, we will use a QQ-plot.
#MLE of lambda (rate)lam<-1/mean(arrive)#1/(n+1), 2/(n+1),..., n/(n+1).quant<-seq(from=1/11,to=10/11,length=10)#produce QQ-plotqqplot(qexp(quant,rate=lam),arrive,xlab="Theoreticalquantiles",ylab="Actual")#add line of equalityabline(0,1)
Given the small dataset, this seems ok – there is no obvious evidence of deviation from the exponential model.
Knowing that the exponential distribution is reasonable, and having an estimate for its rate, is useful to calculate staff scheduling requirements in the A&E.
Extensions of the idea consider flows of patients through the various services (take Math332 Stochastic Processes and/or the STOR-i MRes for more on this).
TheoremExample 12.3.2 Is human body temperature really 98.6 degrees Fahrenheit?
In an article by Mackowiak et al.33Mackowiak P.A., Wasserman, S.S. and Levine, M.M. (1992) A Critical Appraisal of 98.6 Degrees F, the Upper Limit of the Normal Body Temperature and Other Legacies of Carl Reinhold August Wunderlich, the authors measure the body temperatures of a number of individuals to assess whether true mean body temperature is 98.6 degrees Fahrenheit or not. A dataset of individuals is available in the normtemp dataset. The data are assumed to be normally distributed with standard deviation .
Why is this a suitable model?
What assumptions are being made?
Are these assumptions reasonable?
What do the data look like?

The plot can be produced using
The histogram of the data is reasonable, but there might be some skew in the data (right tail).
The normal pdf is given by
where in this case, is known.
The likelihood is then
Since the parameter of interest (in this case ) is continuous, we can differentiate the log-likelihood to find the MLE:
and so
For candidate MLEs we set this to zero and solve, i.e.
and so the MLE is .
This is also the “obvious” estimate (the sample mean). To check it is indeed an MLE, the second derivative of the log-likelihood is
which confirms this is the case.
Using the data, we find .
This might indicate evidence for the body temperature being different from the assumed 98.6 degrees Fahrenheit.
We now check the fit:
> temps <-normtemp$temperature # for shorthand> mean(temps)[1] 98.24923> stdtemp = (temps - mean(temps))/0.73> qqnorm(stdtemp)> abline(0,1) # add "ideal" fit line y = x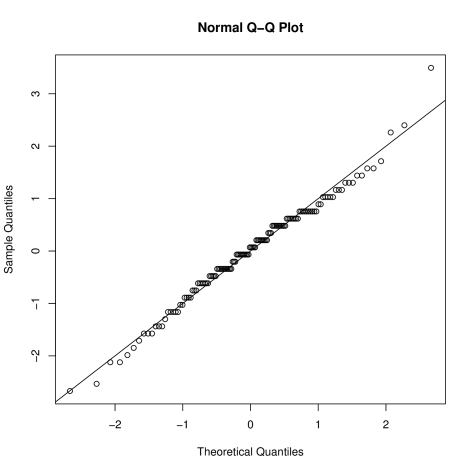
The fit looks good – although (as the histogram previously showed) there is possibly some mild right (positive) skew, indicated by the quantile points above the line.
Why might the QQ-plot show the “stepped” behaviour of the points?

TheoremExample 12.3.3
Every day I cycle to Lancaster University, and have to pass through the traffic lights at the crossroads by Booths (heading south down Scotforth Road). I am either stopped or not stopped by the traffic lights. Over a period of a term, I cycle in 50 times. Suppose that the time I arrive at the traffic lights is independent of the traffic light sequence.
On 36 of the 50 days, the lights are on green and I can cycle straight through. Let be the probability that the lights are on green. Write down the likelihood and log-likelihood of , and hence calculate its MLE.
With the usual iid assumption we see that, if is the number of times the lights are on green then . So we have
We therefore have, for general and ,
and
Solutions to are potential MLEs:
and if we have
For this to be an MLE it must have negative second derivative.
In particular we have and so is the MLE.
Now suppose that over a two week period, on the 14 occasions I get stopped by the traffic lights (they are on red) my waiting times are given by (in seconds)
Assume that the traffic lights remain on red for a fixed amount of time , regardless of the traffic conditions.
Given the above data, write down the likelihood of , and sketch it. What is the MLE of ?
We are going to assume that these waiting times are drawn independently from , where is the parameter we wish to estimate.
Why is this a suitable model?
What assumptions are being made?
Are these assumptions reasonable?
Constructing the likelihood for this example is slightly different from those we have seen before. The pdf of the distribution is
The unusual thing here is that the data enters only through the boundary conditions on the pdf. Another way to write the above pdf is
where is the indicator function.
For data , the likelihood function is then
We can write this as
For our case we have and , so .
We are next asked to sketch this MLE. In R,
> maxx<-19.4> #values of t_r to plot> t<-seq(from=18,to=22,length=1000)>> #likelihood function> uniflik<-function(t){> t^(-14)*(t>=19.4)> }>> plot(t,uniflik(t),type="l")
From the plot it is clear that , since this is the value that leads to the maximum likelihood. Notice that solving would not work in this case, since the likelihood is not differentiable at the MLE.
However, on the feasible range of , i.e. , we have
and so
Remember that derivatives express the rate of change of a function. Hence since the (log-)likelihood is negative ( is strictly positive), then the likelihood is decreasing on the feasible range of parameter values.
Since we are trying to maximise the likelihood, this means we should take the minimum over the feasible range as the MLE. The minimum value on the range is .
12.4 Likelihood Examples: discrete parameters
One case where differentiation is clearly not the right approach to use for maximisation is when the parameter of interest is discrete.
TheoremExample 12.4.1 Illegal downloads
A computer network comprises of computers. The probability of one of these computers to store illegally downloaded files is , independent for each computer. In a particular network it is found that exactly one computer contains illegally downloaded files. Our parameter of interest is .
What is a suitable model for the data?
What assumptions are being made?
Are these assumptions reasonable?
What is the likelihood of ?
Let be the number of computers in the network that contains illegally downloaded files. Then is
Note that the possible values can take are . We can sketch the likelihood for a suitable range of values:
> mrange<-0:20 # value for m=0 will be zero> plot(mrange,dbinom(1,mrange,0.3),xlab="m",ylab="L(m)")
From the plot, we can see that the MLE for is . Alternatively, from the likelihood we have
The likelihood is increasing for , which is equivalent to .
To maximize the likelihood, we want the largest (integer) value of satisfying this constraint, i.e. , hence .
Relative Likelihood intervals
The ratio between two likelihood values is useful to look at for other reasons.
Definition.
Suppose we have data , that arise from a population with likelihood function , with MLE . Then the relative likelihood of the parameter is
The relative likelihood quantifies how likely different values of are relative to the maximum likelihood estimate.
Using this definition, we can construct relative likelihood intervals which are similar to confidence intervals.
Definition.
A p% relative likelihood interval for is defined as the set
TheoremExample 12.4.2 Illegal downloads (cont.)
For example a 50% relative likelihood interval for in our example would be
By plugging in different values of , we see that the relative likelihood interval is . The values in the interval can be seen in the figure below.

TheoremExample 12.4.3 Sequential sampling with replacement: Smarties colours
Suppose we are interested in estimating , the number of distinct colours of Smarties.

In order to estimate , suppose members of the class make a number of draws and record the colour.
Suppose that the data collected (seven draws) were:
purple, blue, brown, blue, brown, purple, brown.
We record whether we had a new colour or repeat:
New, New, New, Repeat, Repeat, Repeat, Repeat.
Let denote the number of unique colours. Then the likelihood function for given the above data is:
If in a second experiment, we observed:
New, New, New, Repeat, New, Repeat, New,
then the likelihood would be:
The MLEs in each case are and .
The plots below show the respective likelihoods.

R code for plotting these likelihoods:
> # experiment 1:> smartlike<-function(m){> L<-1*(m-1)*(m-2)*(3)*(3)*(3)*(3)/m^6> }> mval<-1:15> plot(mval,smartlike(mval))> abline(v=3,col=2)> which.max(smartlike(mval))> # Experiment 2:> # e.g. pink, purple, blue, blue, brown, purple, orange> smartlike2<-function(m){> L<-1*(m-1)*(m-2)*(3)*(m-3)*(4)*(m-4)/m^6> }> dev.new()> plot(mval,smartlike2(mval))> abline(v=8,col=2)> which.max(smartlike2(mval))TheoremExample 12.4.4 Brexit opinions
Three randomly selected members of a class of 10 students are canvassed for their opinion on Brexit. Two are in favour of staying in Europe. What can one infer about the overall class opinion?
The parameter in this model is the number of pro-Remain students in the class, , say. It is discrete, and could take values . The actual true unknown value of is designated by .
Now is
Now since the likelihood function of is the probability (or density) of the observed data for given values of , we have
for .
This function is not continuous (because the parameter is discrete). It can be maximised but not by differentiation.
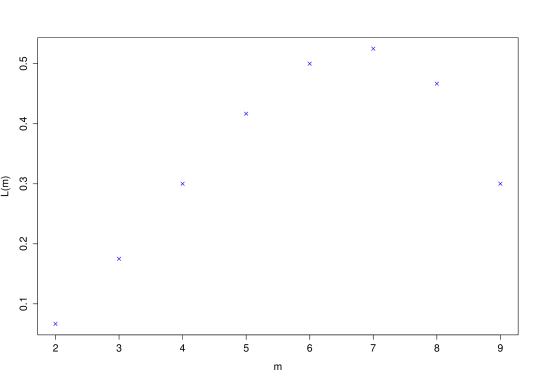 > #likelihood function> L<-function(m){> choose(m,2)*choose(10-m,1)/choose(10,3)> }> #values of m to plot> m<-2:9> plot(m,L(m),pch=4,col="blue")
> #likelihood function> L<-function(m){> choose(m,2)*choose(10-m,1)/choose(10,3)> }> #values of m to plot> m<-2:9> plot(m,L(m),pch=4,col="blue")The maximum likelihood estimate is Note that the points are not joined up in this plot. This is to emphasize the discrete nature of the parameter of interest.
The probability model is an instance of the hypergeometric distribution.
12.5 Summary
{mdframed}A procedure for modelling and inference:
-
1
Subject-matter question needs answering.
-
2
Data are, or become, available to address this question.
-
3
Look at the data – exploratory analysis.
-
4
Propose a model.
-
5
Check the model fits.
-
6
Use the model to address the question.
-
1
The likelihood function is the probability of the observed data for instances of a parameter. Often we use the log-likelihood function as it is easier to work with. The likelihood is a function of an unknown parameter.
-
2
The maximum likelihood estimator (MLE) is the value of the parameter that maximises the likelihood. This is intuitively appealing, and later we will show it is a theoretically justified choice. The MLE should be found using an appropriate maximisation technique.
-
3
If the parameter is continuous, we can often (but not always) find the MLE by considering the derivative of the log-likelihood. If the parameter is discrete, we usually evaluate the likelihood at a range of possible values.
DON’T JOIN UP POINTS WHEN PLOTTING THE LIKELIHOOD FOR A DISCRETE PARAMETER.
DO NOT DIFFERENTIATE LIKELIHOODS OF DISCRETE PARAMETERS!
Chapter 13 Information and Sufficiency
13.1 Introduction
Last time we looked at some more examples of the method of maximum likelihood. When the parameter of interest, , is continuous, the MLE, , can be found by differentiating the log-likelihood and setting it equal to zero. We must then check the second derivative of the log-likelihood is negative (at our candidate ) to verify that we have found a maximum.
Definition.
Suppose we have a sample , drawn from a density with unknown parameter , with log-likelihood . The score function, , is the first derivative of the log-likelihood with respect to :
This is just giving a name to something we have already encountered.
As discussed previously, the MLE solves . Here, is being used to denote the joint density of . For the iid case, . Also, . This is all just from the definitions.
Definition.
Suppose we have a sample , drawn from a density with unknown parameter , with log-likelihood . The observed information function, , is MINUS the second derivative of the log-likelihood with respect to :
Remember that the second derivative of is negative at the MLE (that’s how we check it’s a maximum!). So the definition of observed information takes the negative of this to give something positive.
The observed information gets its name because it quantifies the amount of information obtained from a sample. An approximate 95% confidence interval for (the unobservable true value of the parameter ) is given by
This confidence interval is asymptotic, which means it is accurate when the sample is large. Some further justification on where this interval comes from will follow later in the course.
What happens to the confidence interval as changes?
TheoremExample 13.1.1 Mercedes Benz drivers
You may recall the following example from last year.The website MBClub UK (associated with Mercedes Benz) carried out a poll on the number of times taken to pass a driving test. The results were as follows.
Number of failed attempts 0 1 2 Observed frequency 147 47 20 5 Table 13.1: Number of times taken for drivers to pass the driving test. As always, we begin by looking at the data.
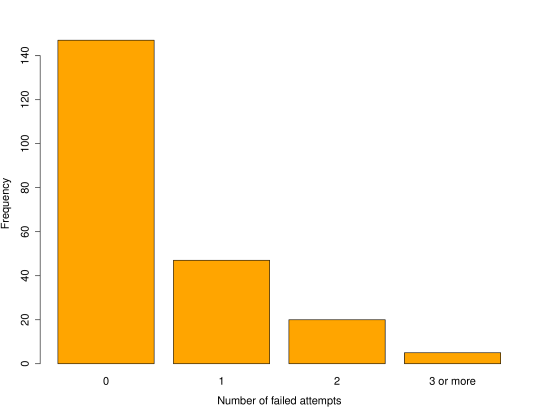 obsdata<-c(147,47,20,5)barplot(obsdata,names.arg=c(0:2, or more'),xlab="Number of failed attempts",ylab="Frequency",col="orange")
obsdata<-c(147,47,20,5)barplot(obsdata,names.arg=c(0:2, or more'),xlab="Number of failed attempts",ylab="Frequency",col="orange")Next, we propose a model for the data to begin addressing the question.
It is proposed to model the data as iid (independent and identically distributed) draws from a geometric distribution.
Why is this a suitable model?
What assumptions are being made?
Are these assumptions reasonable?
The probability mass function (pmf) for the geometric distribution, where is defined as the number of failed attempts, is given by
where .
Assuming that the people in the ‘3 or more’ column failed exactly three times, the likelihood for general data is
and the log-likelihood is
The score function is therefore
A candidate for the MLE, , solves :
-
1
-
2
-
3
-
4
To confirm this really is an MLE we need to verify it is a maximum, i.e. a negative second derivative.
In this case the function is clearly negative for all , if not we would just need to check this is the case at the proposed MLE.
Now plugging in the numbers, and , we get
This is the same answer as the ‘obvious one’ from intuition.
But now we can calculate the observed information at , and use this to construct a 95% confidence interval for .
Now the 95% confidence interval is given by
We should also check the fit of the model by plotting the observed data against the theoretical data from the model (with the MLE plugged in for ).
#value of theta: MLEmletheta<-0.682#expected data countsexpdata<-219*c(dgeom(0:2,mletheta),1-pgeom(2,mletheta))#make plotbarplot(rbind(obsdata,expdata),names.arg=c(0:2, or more'),xlab="Number of failed attempts",ylab="Frequency",col=c("orange","red"),beside=T)#add legendlegend("topright",c("observed","expected"),col=c("orange","red"),lty=1)
We can do actually do slightly better than this.
We assumed ‘the people in the “3 or more” column failed exactly three times’. With likelihood we don’t need to do this. Remember: the likelihood is just the joint probability of the data. In fact, people in the “3 or more” group have probability
We could therefore write the likelihood more correctly as
where if and if .
NOTE: if all we know about an observation is that it exceeds some value, we say that is censored. This is an important issue with patient data, as we may lose contact with a patient before we have finished observing them. Censoring is dealt with in more generality MATH335 Medical Statistics.
What is the MLE of using the more correct version of the likelihood?
The term in the second product (for the censored observations) can be seen as a geometric progression with constant term and common ratio , and so (check that this is the case).
Hence the likelihood can be written
where the sum of ’s only involves the uncensored observations, denotes the number of uncensored observations, and is the number of censored observations.
The log-likelihood becomes .
Differentiating, the score function is
A candidate MLE solves , giving
The value of the MLE using these data is .
Compare this to the original MLE of 0.682.
Why is the new estimate different to this?
Why is the difference small?
13.2 Suppression of Information
Last time we introduced the score function (the derivative of the log-likelihood), and the observed information function (MINUS the second derivative of the log-likelihood). The score function is zero at the MLE. The observed information function evaluated at the MLE gives us a method to construct confidence intervals.
We will now study the concept of observed information in more detail.

TheoremExample 13.2.1 Human Genotyping
Humans are a diploid species, which means you have two copies of every gene (one from your father, one from your mother). Genes occur in different forms; this is what leads to some of the different traits you see in humans (e.g. eye colour). Mendelian traits are a special kind of trait that are determined by a single gene.
Having wet or dry earwax is a Mendelian trait. Earwax wetness is controlled by the gene ABCC11 (this gene lives about half way along chromosome 16). We will call the wet earwax version of ABCC11 W, and the dry version w. The wet version is dominant, which means you only need one copy of W to have wet earwax. Both copies of the gene need to be w to get dry earwax.
The Hardy-Weinberg law of genetics states that if W occurs in a (randomly mating) population with proportion (so w occurs with proportion ) potential combinations in humans obey the proportions:
combination WW Ww ww proportion Suppose I take a sample of 100 people and assess the wetness of their earwax. I observe that 87 of the people have wet earwax and 13 of them have dry earwax.
I am actually interested in , the proportion of copies of W in my population.
Show that the probability of a person having wet earwax is , and that the probability of a person having dry earwax is . Also show that these two probabilities sum to .
The number of people with wet earwax in my sample is therefore . So
IMPORTANT FACT: when writing down the likelihood, we can always omit multiplicative constants, since they become additive in the log-likelihood, then disappear in the differentation. A multiplicative constant is one that does not depend on the parameter of interest (here ).
So we can write down the likelihood as
So the log likelihood is
(plus constant).
Now is a continuous parameter so a suitable way to find a candidate MLE is to differentiate. The score function is
We can solve ; it is as a quadratic in :
-
1
-
2
-
3
This gives two solutions but we need as it is a proportion, so get as our potential MLE.
The second derivative is
This is clearly at , confirming that it is a maximum.
The observed information is obtained by substituting into , giving
Hence an approximate 95% confidence interval for is given by
After all that derivation, don’t forget the context. This is a 95% confidence interval for the proportion of people with a W variant of ABCC11 gene in the population of interest.
Suppose that, instead of looking in people’s ears to see whether their wax is wet or dry we decide to genotype them instead, thereby knowing whether they are WW, Ww or ww.
This is a considerably more expensive option (although perhaps a little less disgusting) so a natural question is: what do we gain by doing this?
We take the same 100 people and find that 42 are WW, 45 are Ww and 13 are ww. Think about how this relates back to the earwax wetness. Did we need to genotype everyone?
The likelihood function for given our new information is
The log-likelihood is
where is a constant.
As before, is continuous so we can find candidates for the MLE by differentiating:
Now solving gives a candidate MLE
-
1
,
-
2
,
i.e.
This is our potential MLE. Checking the second derivative
which is at confirming that it is a maximum.
The observed information is obtained by substituting into , giving
Hence an approximate 95% confidence interval for is given by
Now, compare the confidence intervals and the observed informations from the two separate calculations. What do you conclude?
Of course, genotyping the participants of the study is expensive, so may not be worthwhile. If this was a real problem, the statistician could communicate the figures above to the geneticist investigating gene ABCC11, who would then be able to make an evidence-based decision about how to conduct the experiment.
13.3 Sufficiency
Recall the driving test data from the Example 13.1.
Number of failed attempts 0 1 2 Observed frequency 147 47 20 5 Table 13.2: Number of times taken for drivers to pass the driving test. We chose to model these data as being geometrically distributed. Assuming that the people in the ‘3 or more’ column failed exactly three times, the log-likelihood for general data is
Now, suppose that, rather than being presented with the table of passing attempts, you were simply told that with 219 people filling in the survey, .
Would it still be possible to proceed with fitting the model?
The answer is yes; moreover, we can proceed in exactly the same way, and achieve the same results! This is because, if you look at the log-likelihood, the only way in which the data is involved is through , meaning that in some sense, this is all we need to know.
This is clearly a big advantage, we just have to remember one number rather than an entire table.
We call a sufficient statistic for .
Definition.
Let be a sample from . Then a function of the data is said to be a sufficient statistic for (or sufficient for ) if is independent of given , i.e.
Some consequences of this definition:
-
1
For the objective of learning about , if I am told , there is no value in being told anything else about .
-
2
If I have two datasets and , and , then I should make the same conclusions about from both, even if .
-
3
Sufficient statistics always exist since trivially always satisfies the above definition.
Definition.
Let be a sample from . Let be sufficient for . Then is said to be minimally sufficient for if there is no sufficient statistic with a lower dimension than .
Theorem (Neyman factorisation theorem).
Let be a sample from . Then a function is sufficient for if and only if the likelihood function can be factorised in the form
where is a function of the data only, and is a function of the data only through .
For a proof see page 276 of Casella and Berger.
We can also express the factorisation result in terms of the log-likelihood, which is often easier, just by taking logs of the above result:
where and .
We can show that is sufficient for in the driving test example by inspection of the log-likelihood:
Letting , then , and , we have satisfied the factorisation criterion, and hence is sufficient for .
Suppose that I carry out another survey on attempts to pass a driving test, again with participants and get data , with but . Are the following statements true or false?
-
1
, the MLE based on data , is the same as , the MLE based on data .
-
2
The confidence intervals based on both datasets will be identical.
-
3
The geometric distribution is appropriate for both datasets.
An important shortcoming in only considering the sufficient statistic is that it does not allow us to check how well the chosen model fits.
TheoremExample 13.3.1 Poisson parameter (cont.)
Recall from the beginning of this section, the London homicides data, which we modelled as a random sample from the Poisson distribution. We found
and that the log-likelihood function for the Poisson data is consequently
with the MLE being
By differentiating again, we can find the information function
and so
What is a sufficient statistic for the Poisson parameter?
For this case, we can let , and , and , we have satisfied the factorisation criterion, and hence is sufficient for .
TheoremExample 13.3.2 Normal variance
Suppose the sample comes from . Find a sufficient statistic for . Is the MLE a function of this statistic or of the sample mean? Give a formula for the 95% confidence interval of .
First, the density is given by
leading to the likelihood
-
1
-
2
Hence, is a sufficient statistic for . The log-likelihood and score functions are
-
1
-
2
Solving gives a candidate MLE
which is a function of the sufficient statistic. To check this is an MLE we calculate
In this case it isn’t immediately obvious that , but substituting in
confirming that this is an MLE.
The observed information is ,
Therefore a 95% confidence interval is given by
13.4 Summary
{mdframed}-
1
The score function is the first derivative of the log-likelihood. The observed information is MINUS the second derivative of the log-likelihood. It will always be positive when evaluated at the MLE.
DO NOT FORGET THE MINUS SIGN!
-
2
The likelihood function adjusts appropriately when more information becomes available. Observed information does what it says. Higher observed information leads to narrower confidence intervals. This is a good thing as narrower confidence intervals mean we are more sure about where the true value lies.
For a continuous parameter of interest, , the calculation of the MLE and its confidence interval follows the steps:
-
1
Write down the likelihood, .
-
2
Write down the log-likelihood, .
-
3
Work out the score function, .
-
4
Solve to get a candidate for the MLE, .
-
5
Work out . Check it is negative at the MLE candidate to verify it is a maximum.
-
6
Work out the observed information, .
-
7
Calculate the confidence interval for :
-
1
-
3
Changing the data that your inference is based on will change the amount of information, and subsequent inference (e.g. confidence intervals).
-
4
A statistic is said to be sufficient for a parameter , if is independent of when conditioning on .
-
5
An equivalent, and easier to demonstrate condition is that the likelihood can be factorised in the form , iff is sufficient.
Chapter 14 Distribution of the MLE
14.1 Recalling randomness
We have noted that an asymptotic 95% confidence interval for a true parameter, , is given by
where is the MLE and
is the observed information.
In this lecture we will sketch the derivation of the distribution of the MLE, and show why the above really is an asymptotic 95% confidence interval for .
Recall the distinction between an estimate and an estimator.
Given a sample , an estimator is any function of that sample. An estimate is a particular numerical value produced by the estimator for given data .
The maximum likelihood estimator is a random variable; therefore it has a distribution. A maximum likelihood estimate is just a number, based on fixed data.
For the rest of this lecture we consider an iid sample , from some distribution with unknown parameter , and the MLE (maximum likelihood estimator) .
Definition.
The Fisher information of a random sample is the expected value of minus the second derivative of the log-likelihood, evaluated at the true value of the parameter:
This is related to, but different from, the observed information.
-
1
The observed information is calculated based on observed data; the Fisher information is calculated taking expectations over random data.
-
2
The observed information is calculated at , the Fisher information is calculated at .
-
3
The observed information can be written down numerically; the Fisher information usually cannot be since it depends on , which is unknown.
TheoremExample 14.1.1 Fisher Information for a Poisson parameter
Suppose is a random sample from . Find the Fisher information. Remember that . For ,
where is a constant.
-
1
-
2
-
3
-
4
Hence
We see that our answer is in terms of , which is unknown (and not in terms of the data!) The Fisher information is useful for many things in likelihood inference, to see more take MATH330 Likelihood Inference.
Here, it features in the most important theorem in the course.
Theorem (Asymptotic distribution of the maximum likelihood estimator).
Suppose we have an iid sample from some distribution with unknown parameter , with maximum likelihood estimator . Then (under certain regularity conditions) in the limit as
This says that, for large, the distribution of the MLE is approximately normal with mean equal to the true value of the parameter, and variance equal to the reciprocal of the Fisher information.
We will not prove the result in this course, but it has to do with the central limit theorem (from MATH230).
Turning this around, this means that, for large ,
This result is useless as it stands, because we can only calculate when we know , and if we know it, why are we constructing a confidence interval for it?!
Luckily, the result also works asymptotically if we replace by , giving that
is an approximate 95% confidence interval for (as claimed earlier).
Exam Question
A large batch of electrical components contains a proportion which are defective and not repairable, a proportion which are defective but repairable and a proportion which are satisfactory.
-
(a)
What values of are admissible?
Fifty components are selected at random (with replacement) from the batch, of which 2 are defective and not repairable, 5 are defective and repairable and 43 are satisfactory.
-
(b)
Write down the likelihood function, and make a rough sketch of it.
-
(c)
Obtain the maximum likelihood estimate of .
-
(d)
Obtain an approximate 95% confidence interval for . A value of equal to 0.02 is believed to represent acceptable quality for the batch. Do the data support the conclusion that the batch is of acceptable quality?
Solution:
-
a
There are 3 types of component, each giving rise to a constraint on :
-
1
,
-
2
,
-
3
,
as the components each need to have valid probabilities. The third inequality is sufficient for the other two and gives .
-
1
-
b
Given the data, the likelihood is
For the sketch note that and the function is concave and positive between these two with a maximum closer to than .
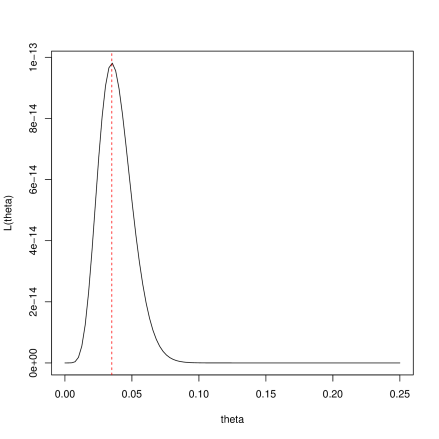
-
c
To work out the MLE, we differentiate the (log-)likelihood as usual. The log-likelihood is
Differentiating,
A candidate MLE solves , giving .
Moreover,
so this is indeed the MLE.
-
d
The observed information is
So a confidence interval for is
As is within this confidence interval there is no evidence of this batch being sub-standard.
14.2 Summary
{mdframed}-
1
Under certain regularity conditions, the maximum likelihood estimator has, asymptotically, a normal distribution with mean equal to the true parameter value, and variance equal to the inverse of the Fisher information.
-
2
The Fisher information is minus the expectation of the second derivative of the log-likelihood evaluated at the true parameter value.
-
3
Based on this, we can construct approximate 95% confidence intervals for the true parameter value based on the MLE and the observed information.
-
4
Importantly, this is an asymptotic result so is only approximate. In particular, it is a bad approximation to a 95% confidence interval when the sample size, , is small.
Chapter 15 Deviance and the LRT
15.1 Deviance-based confidence intervals
In the last lecture we showed that the MLE is asymptotically normally distributed, and we use this fact to construct an approximate 95% confidence interval.
In this lecture we will introduce the concept of deviance, and show that this leads to another way to calculate approximate confidence intervals that have various advantages.
We will begin by showing through an example where things can go wrong with the confidence intervals we know (and love?).

TheoremExample 15.1.1 An evening at the casino
On a fair (European) roulette wheel there is a probability of each number coming up.
In the early 1990s, Gonzalo Garcia-Pelayo believed that casino roulette wheels were not perfectly random, and that by recording the results and analysing them with a computer, he could gain an edge on the house by predicting that certain numbers were more likely to occur next than the odds offered by the house suggested. This he did at the Casino de Madrid in Madrid, Spain, winning 600,000 euros in a single day, and one million euros in total.
Legal action against him by the casino was unsuccessful, it being ruled that the casino should fix its wheel:
Suppose I am curious that the number 17 seems to come up on a casino’s roulette wheel more frequently than other numbers. I track it for 30 spins, during which it comes up 2 times. I decide to carry out a likelihood analysis on , the probability of the number 17 coming up, and its confidence interval.
We propose to model the situation as follows. Let be the number of times the number 17 comes up in 30 spins of the roulette wheel. We decide to model .
Why is this a suitable model?
What assumptions are being made?
Are these assumptions reasonable?
The probability of the observed data is given by
The likelihood is simply the probability of the observed data, but we can ignore the multiplicative constants, so
The log-likelihood is
Differentiating,
Now remember solutions to are potential MLEs:
-
1
-
2
-
3
The second derivative will both tell us whether this is a maximum, and provide the observed information:
This is clearly negative for all , so must be a maximum.
Moreover, the observed information is
A 95% confidence interval for is given by
which, on substituting in and the observed information becomes
The resulting confidence interval includes negative values (for a probability parameter). What’s the problem??
Let’s look at a plot of the log-likelihood for the above situation.
loglik<-function(p){2*log(p) + 28*log(1-p)}p<-seq(from=0.01,to=0.25,length=1000)plot(p,loglik(p),type="l")
We notice that the log-likelihood is quite asymmetric. This happens because the MLE is close to the edge of the feasible space (i.e. close to 0). The confidence interval defined above is forced to be symmetric, which seems inappropriate here.
Definition.
Suppose we have a log-likelihood function with unknown parameter , . Then the deviance function is given by
Notice that , and .
What can we say about ?
This is a fixed (but unknown) value for fixed data . However, in similar spirit to the last lecture, we can consider random data . Now, the deviance function depends on (since different data leads to different likelihoods). So, is a random variable.
Theorem 2 (Asymptotic distribution of the deviance).
Suppose we have an iid sample from some distribution with unknown parameter . Then (under certain regularity conditions) in the limit as ,
i.e. the deviance of the true value of has a distribution with one degree of freedom.
The practical upshot of this result is that we have another way to construct a confidence interval for . A 95% confidence interval for , for example, is given by , i.e. any values of whose deviance is smaller than 3.84.
TheoremExample 15.1.2 An evening at the casino continued
This property of the deviance is best seen visually. Going back to the roulette data:

From the graph we can estimate the confidence interval based on the deviance. In fact the exact answer to three decimal places is . Notice that this is not symmetrical, and that all values in the interval are feasible.
The original motivation for all of this was that we were wondering if the number 17 comes up more often than with the 1/37 that should be observed in a fair roulette wheel.
In fact 1/37=0.027, which is within the 95% confidence interval calculated above. Hence there is insufficient evidence (so far) to support the claim that this number is coming up more often than it should.
Notes (summary)
-
1
We have now seen two different ways to calculate approximate confidence intervals (CI) for an unknown parameter. Previously, we calculated CI based on the asymptotic distribution of the MLE (CI-MLE). Here, we showed how to calculate the CI based on the asymptotic distribution of the deviance (CI-D).
-
2
We discussed various differences and pros and cons of the two:
-
1
CI-MLE is always symmetric about the MLE. CI-D is not.
-
2
CI-MLE can include values with zero likelihood (e.g. infeasible values such as negative probabilities, as seen here). CI-D will only include feasible values.
-
3
CI-D is typically harder to calculate than CI-MLE.
-
4
For reasons we will not go into here, CI-D is typically more accurate than CI-MLE.
-
5
CI-D is invariant to re-parametrization; CI-MLE is not. (This is a good thing for CI-D, that we will learn more about in subsequent lectures).
-
1
-
3
Overall, CI-D is usually preferred to CI-MLE (since the only disadvantage is that it is harder to compute).
-
4
DEVIANCES ARE ALWAYS NON-NEGATIVE!
15.2 Re-parametrization and Invariance
TheoremExample 15.2.1 Accident and Emergency continued
In our likelihood examples we discussed modelling inter-arrival times at an A&E department using an Exponential distribution. The exponential pdf is given by
for and , where is the rate parameter.
Based on the inter-arrival times (in minutes):
giving , we came up with the MLE for of .
Now, .
How would we go about finding an estimate for ?
Method 1: re-write the pdf as
where and , to give a likelihood of
then find the MLE by the usual approach.
Method 2: Since , presumably .
Which method is more convenient?
Which method appears more rigorous?
In fact, both methods give the same solution always. This property is called invariance to reparameterization of the MLE. It is a nice property both because it agrees with our intuition, and saves us a lot of potential calculation.
Theorem (Invariance of MLE to reparametrisation.).
If is the MLE of and is a monotonic function of , , then the MLE of is .
Proof.
Write . The likelihood for is , and for is . Note that as is monotonic and define by . To show that is the MLE,
as is MLE. But
∎
This means that both methods above must give the same answer.
Exercise.
Show this works for the case above, by demonstrating that Method 1 leads to .
The following corollary follows immediately from invariance of the MLE to reparametrisation.
Corollary.
Confidence intervals based on the deviance are invariant to reparametrisation, in the sense that
Proof.
by Theorem above, which equals
∎
The practical consequence of this is that if
is a deviance confidence interval with coverage for ,
then
is a deviance confidence interval with coverage for .
(Of course, ).
IMPORTANT: This simple translation does not hold for confidence intervals based on the asymptotic distribution to the MLE. This is because that depends on the second derivative of with respect to the parameter, which will be different in more complicated ways for different parameter choices.
This will be explored more in MATH330 Likelihood Inference.
Exam Question
-
a
The random variables are independent and identically distributed with the geometric distribution
where is a parameter in the range of to be estimated. The mean of the above geometric distribution is .
-
i
Write down formulae for the maximum likelihood estimator for and for Fisher’s information;
-
ii
Write down what you know about the distribution of the maximum likelihood estimator for this example when is large.
-
i
-
b
In a particular experiment, , .
-
i
Compute an approximate 95% confidence interval for based on the asymptotic distribution of the maximum likelihood estimator;
-
ii
Compute the deviance and sketch it over the range . Use your sketch to describe how to use the deviance to obtain an approximate 95% confidence interval for ;
-
iii
If you were asked to produce an approximate 95% confidence interval for the mean of the distribution , what would be your recommended approach? Justify your answer.
-
i
Solution:
-
a
-
i
For the model, the likelihood function is
The log-likelihood is then
with derivative
A candidate MLE solves , giving
Moreover,
so this is indeed the MLE.
For the Fisher Information,
after simplification, since .
-
ii
Using the Fisher information, the asymptotic distribution of the MLE is
-
i
-
b
-
i
Using the data, the MLE is . The observed information is
Therefore a confidence interval is
-
ii
The deviance is given by
To plot the deviance calculate and , and note that . A confidence interval is obtained by drawing a horizontal line at 3.84; the interval is all with .
-
iii
To construct a confidence interval for the mean, we would use the mean function on the deviance-based confidence interval just calculated, as this is invariant to re-parametrization.
-
i
15.3 Summary
{mdframed}-
1
The simple, intuitive answer is true: if is a MLE, then if for any monotonic transformation , then .
-
2
The same simple result can be applied to confidence intervals based on the deviance, but can NOT be applied to confidence intervals based on the asymptotic distribution of the MLE.
-
-
-