Style control - access keys in brackets
13.1 Introduction
Last time we looked at some more examples of the method of maximum likelihood. When the parameter of interest, , is continuous, the MLE, , can be found by differentiating the log-likelihood and setting it equal to zero. We must then check the second derivative of the log-likelihood is negative (at our candidate ) to verify that we have found a maximum.
Definition.
Suppose we have a sample , drawn from a density with unknown parameter , with log-likelihood . The score function, , is the first derivative of the log-likelihood with respect to :
This is just giving a name to something we have already encountered.
As discussed previously, the MLE solves . Here, is being used to denote the joint density of . For the iid case, . Also, . This is all just from the definitions.
Definition.
Suppose we have a sample , drawn from a density with unknown parameter , with log-likelihood . The observed information function, , is MINUS the second derivative of the log-likelihood with respect to :
Remember that the second derivative of is negative at the MLE (that’s how we check it’s a maximum!). So the definition of observed information takes the negative of this to give something positive.
The observed information gets its name because it quantifies the amount of information obtained from a sample. An approximate 95% confidence interval for (the unobservable true value of the parameter ) is given by
This confidence interval is asymptotic, which means it is accurate when the sample is large. Some further justification on where this interval comes from will follow later in the course.
What happens to the confidence interval as changes?
TheoremExample 13.1.1 Mercedes Benz drivers
You may recall the following example from last year.The website MBClub UK (associated with Mercedes Benz) carried out a poll on the number of times taken to pass a driving test. The results were as follows.
| Number of failed attempts | 0 | 1 | 2 | |
| Observed frequency | 147 | 47 | 20 | 5 |
As always, we begin by looking at the data.
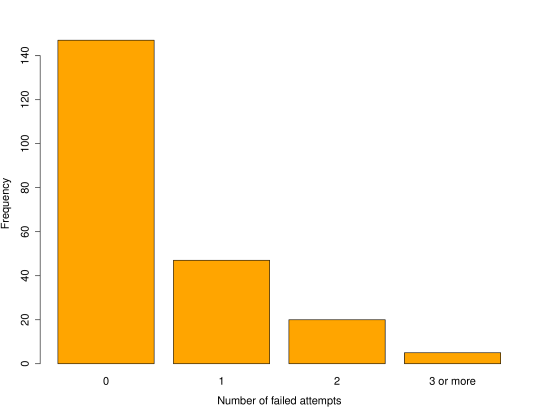
Next, we propose a model for the data to begin addressing the question.
It is proposed to model the data as iid (independent and identically distributed) draws from a geometric distribution.
Why is this a suitable model?
What assumptions are being made?
Are these assumptions reasonable?
The probability mass function (pmf) for the geometric distribution, where is defined as the number of failed attempts, is given by
where .
Assuming that the people in the ‘3 or more’ column failed exactly three times, the likelihood for general data is
and the log-likelihood is
The score function is therefore
A candidate for the MLE, , solves :
-
1
-
2
-
3
-
4
To confirm this really is an MLE we need to verify it is a maximum, i.e. a negative second derivative.
In this case the function is clearly negative for all , if not we would just need to check this is the case at the proposed MLE.
Now plugging in the numbers, and , we get
This is the same answer as the ‘obvious one’ from intuition.
But now we can calculate the observed information at , and use this to construct a 95% confidence interval for .
Now the 95% confidence interval is given by
We should also check the fit of the model by plotting the observed data against the theoretical data from the model (with the MLE plugged in for ).

We can do actually do slightly better than this.
We assumed ‘the people in the “3 or more” column failed exactly three times’. With likelihood we don’t need to do this. Remember: the likelihood is just the joint probability of the data. In fact, people in the “3 or more” group have probability
We could therefore write the likelihood more correctly as
where if and if .
NOTE: if all we know about an observation is that it exceeds some value, we say that is censored. This is an important issue with patient data, as we may lose contact with a patient before we have finished observing them. Censoring is dealt with in more generality MATH335 Medical Statistics.
What is the MLE of using the more correct version of the likelihood?
The term in the second product (for the censored observations) can be seen as a geometric progression with constant term and common ratio , and so (check that this is the case).
Hence the likelihood can be written
where the sum of ’s only involves the uncensored observations, denotes the number of uncensored observations, and is the number of censored observations.
The log-likelihood becomes .
Differentiating, the score function is
A candidate MLE solves , giving
The value of the MLE using these data is .
Compare this to the original MLE of 0.682.
Why is the new estimate different to this?
Why is the difference small?